Advanced Apache Kafka Anatomy: Delving Deep into the Core Components
Apache Kafka has become a cornerstone of modern data architectures, renowned for its ability to handle high-throughput, low-latency data streams. While its fundamental concepts are widely understood, a deeper dive into Kafka’s advanced components and features reveals the true power and flexibility of this distributed event streaming platform. This blog aims to unravel the advanced anatomy of Apache Kafka, offering insights into its core components, configurations, and best practices for optimizing performance.
Core Components of Kafka
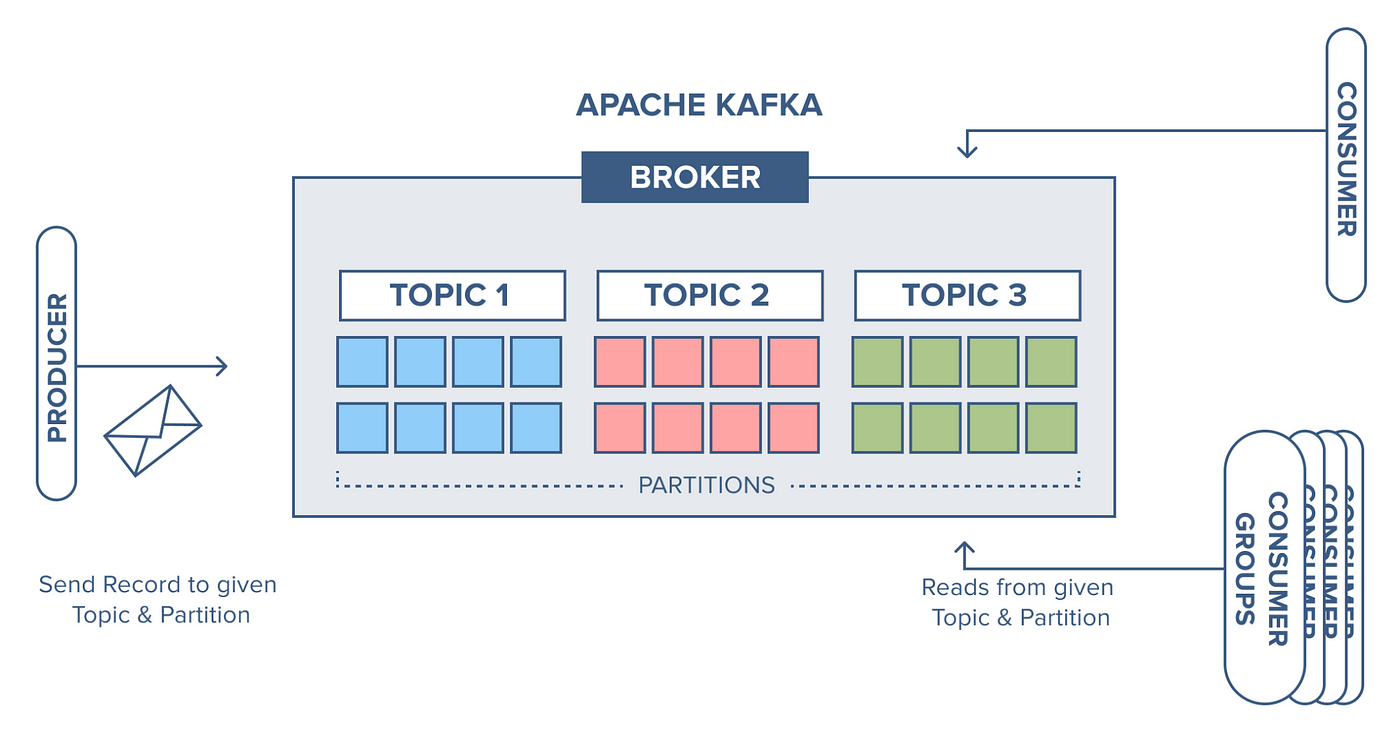
Brokers
Brokers are the backbone of a Kafka cluster, responsible for managing data storage, processing requests from clients, and replicating data to ensure fault tolerance.
 Source: Internet
Source: Internet
- Leader and Follower Roles: Each topic partition has a leader broker that handles all read and write requests for that partition, while follower brokers replicate the leader’s data to ensure high availability.
- Scalability: Kafka’s design allows for easy scaling by adding more brokers to distribute the load and improve throughput.
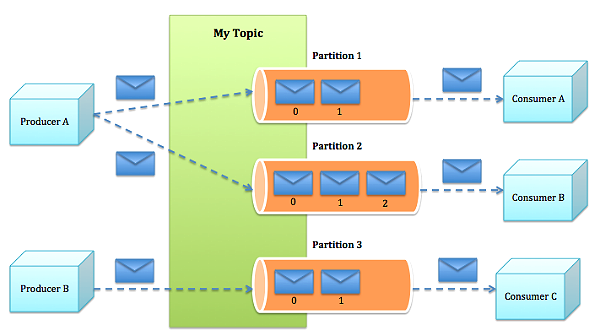
Topics and Partitions
Topics are categories to which records are published. Each topic can be divided into multiple partitions, which are the basic unit of parallelism and scalability in Kafka.
- Partitioning Strategy: Proper partitioning is crucial for load balancing and ensuring efficient data distribution across the cluster. Common strategies include key-based partitioning and round-robin distribution.
- Replication: Partitions can be replicated across multiple brokers to provide redundancy and high availability. The replication factor determines the number of copies of a partition in the cluster.
Producers
Producers are responsible for publishing records to Kafka topics.
 Source: Internet
Source: Internet
- Acknowledgments: Configurable acknowledgment settings (
acks) determine how many broker acknowledgments the producer requires before considering a request complete (acks=0,acks=1, oracks=all). - Batching and Compression: Producers can batch multiple records into a single request to improve throughput and enable data compression to reduce the size of the data being transferred.
Consumers
Consumers subscribe to topics and process the records published to them.
- Consumer Groups: Consumers operate as part of a group, where each consumer in a group reads from a unique set of partitions. This allows for parallel processing and ensures that records are processed by a single consumer.
- Offset Management: Consumers track their position in each partition by maintaining offsets, which can be automatically committed at intervals or manually managed for precise control over record processing.
ZooKeeper
ZooKeeper is a critical component in Kafka’s ecosystem, used for cluster coordination and configuration management.
- Leader Election: ZooKeeper helps manage the leader election process for partition leaders and the Kafka controller.
- Metadata Storage: Stores metadata about the Kafka cluster, including broker information, topic configurations, and access control lists.
Advanced Kafka Features
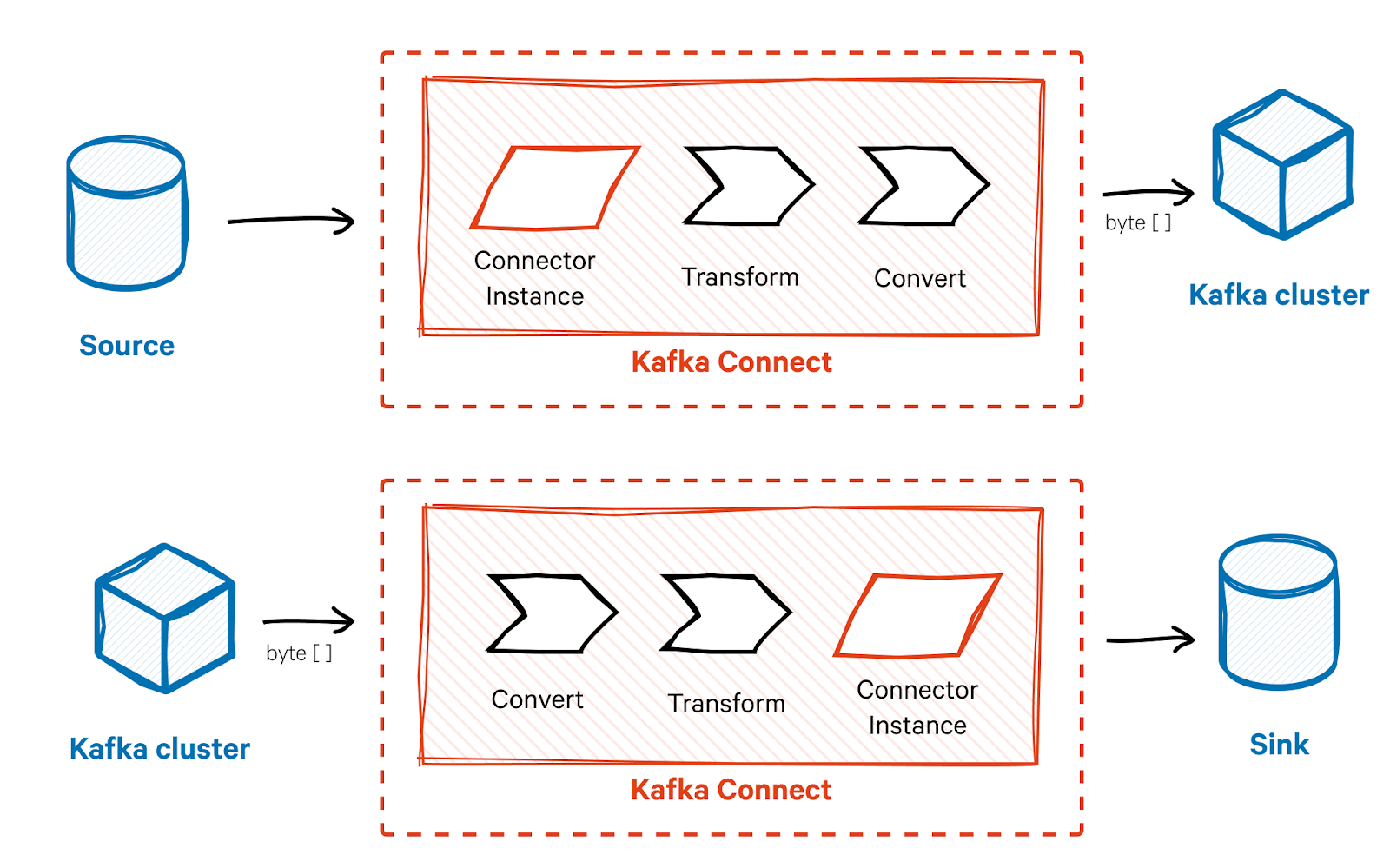
Kafka Connect
Kafka Connect is a robust framework for integrating Kafka with external systems.
 Source: Internet
Source: Internet
- Source Connectors: Import data from external systems (e.g., databases, file systems) into Kafka topics.
- Sink Connectors: Export data from Kafka topics to external systems (e.g., databases, data lakes).
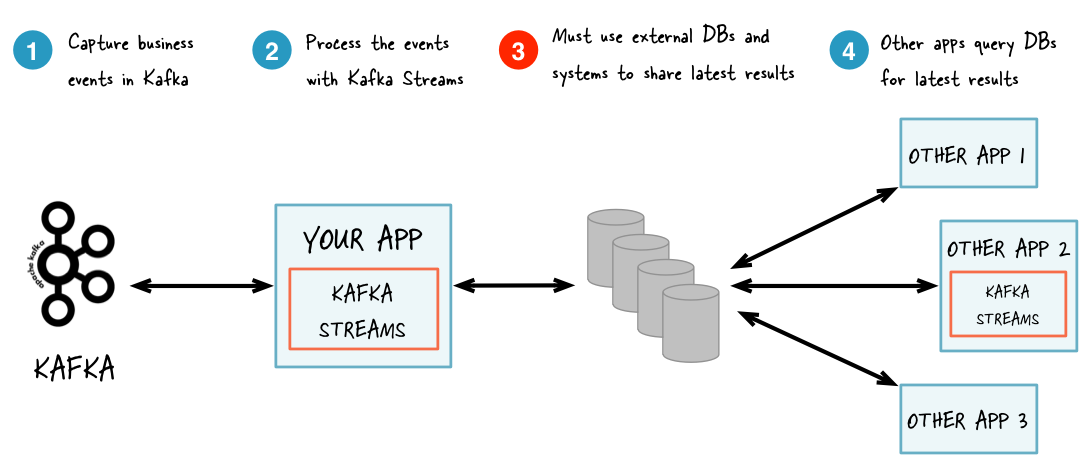
Kafka Streams
Kafka Streams is a powerful library for building stream processing applications on top of Kafka.
 Source: Internet
Source: Internet
- KStream and KTable: Core abstractions for modeling streams of records and tables of changelog records, respectively.
- Stateful Processing: Enables operations like joins, aggregations, and windowing, with support for local state stores and fault-tolerant state management.
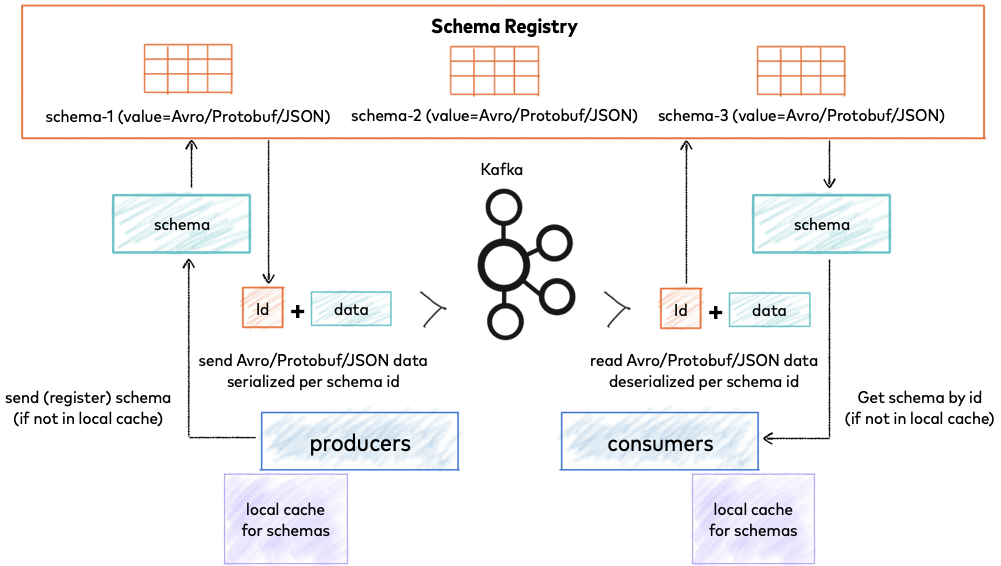
Schema Registry
Schema Registry is a centralized service for managing and validating schemas used by Kafka producers and consumers.
 Source: Internet
Source: Internet
- Avro, JSON, and Protobuf: Supports multiple schema formats, ensuring data consistency and compatibility across different applications.
- Schema Evolution: Facilitates schema versioning and evolution, allowing for backward and forward compatibility.
Best Practices for Kafka Performance Optimization
Configuring Brokers
- Heap Size: Set an appropriate heap size for Kafka brokers to prevent memory issues. Typically, 4-8 GB is recommended.
- Log Retention: Configure log retention policies (
log.retention.hours,log.retention.bytes) to manage disk usage and comply with data retention requirements.
Optimizing Producers
- Batch Size and Linger: Adjust
batch.sizeandlinger.msto balance latency and throughput. Larger batch sizes and longer linger times can improve throughput at the cost of increased latency. - Compression Type: Enable compression (
compression.type) to reduce network bandwidth usage. Common options includegzip,snappy, andlz4.
Tuning Consumers
- Fetch Size: Configure
fetch.min.bytesandfetch.max.wait.msto control the amount of data fetched in each request and the maximum wait time, balancing latency and throughput. - Offset Commit Frequency: Adjust
auto.commit.interval.msfor automatic offset commits or implement manual offset management for finer control over record processing.
Ensuring High Availability
- Replication Factor: Set an appropriate replication factor for topics to ensure data redundancy and fault tolerance. A replication factor of 3 is common in production environments.
- ISR (In-Sync Replicas): Monitor the number of in-sync replicas (
min.insync.replicas) to ensure that there are enough replicas to maintain data consistency and durability.
Conclusion
Apache Kafka’s advanced anatomy reveals a powerful and flexible system capable of handling the most demanding data streaming requirements. By understanding its core components, leveraging advanced features like Kafka Connect and Kafka Streams, and adhering to best practices for performance optimization, you can harness the full potential of Kafka in your data architecture. Whether you’re building real-time analytics, event-driven microservices, or data integration pipelines, Kafka provides the foundation for scalable, resilient, and high-performance data streaming solutions.