Buddhi: Pushing the Boundaries of Long-Context Open-Source AI
AI Planet has introduced Buddhi-128K-Chat-7B, an open-source chat model distinguished by its expansive 128,000-token context window. This advancement enables the model to process and retain extensive contextual information, enhancing its performance in tasks requiring deep context understanding.
 Source: Internet
Source: Internet
Model Architecture
Buddhi-128K-Chat-7B is fine-tuned from the Mistral-7B Instruct v0.2 base model, selected for its superior reasoning capabilities. The Mistral-7B architecture incorporates features such as Grouped-Query Attention and a Byte-fallback BPE tokenizer, originally supporting a maximum of 32,768 position embeddings. To extend this to 128K, the Yet another Rope Extension (YaRN) technique was employed, modifying positional embeddings to accommodate the increased context length.
Dataset Composition
The training dataset comprises three sections tailored for chat model development:
- Stack Exchange Data: Consists of question-and-answer pairs, refined using the Mistral model to enhance formatting for chat applications.
- PG19-Based Data with Alpaca Formatting: Utilizes the PG19 dataset as context, with question-answer pairs generated by GPT-3.
- PG19-Based Data with GPT-4: Similar to the previous section but with question-answer pairs generated by GPT-4, ensuring a diverse conversational scope.
This strategic composition ensures comprehensive coverage of dialogue scenarios, optimizing the model’s performance across various contexts.
Benchmark Performance
Buddhi-128K-Chat-7B has been evaluated using both short and long context benchmarks:
Short Context Benchmarks: The model’s performance on tasks like HellaSwag, ARC Challenge, MMLU, TruthfulQA, and Winogrande has been assessed, with metrics available on the Open LLM Leaderboard.
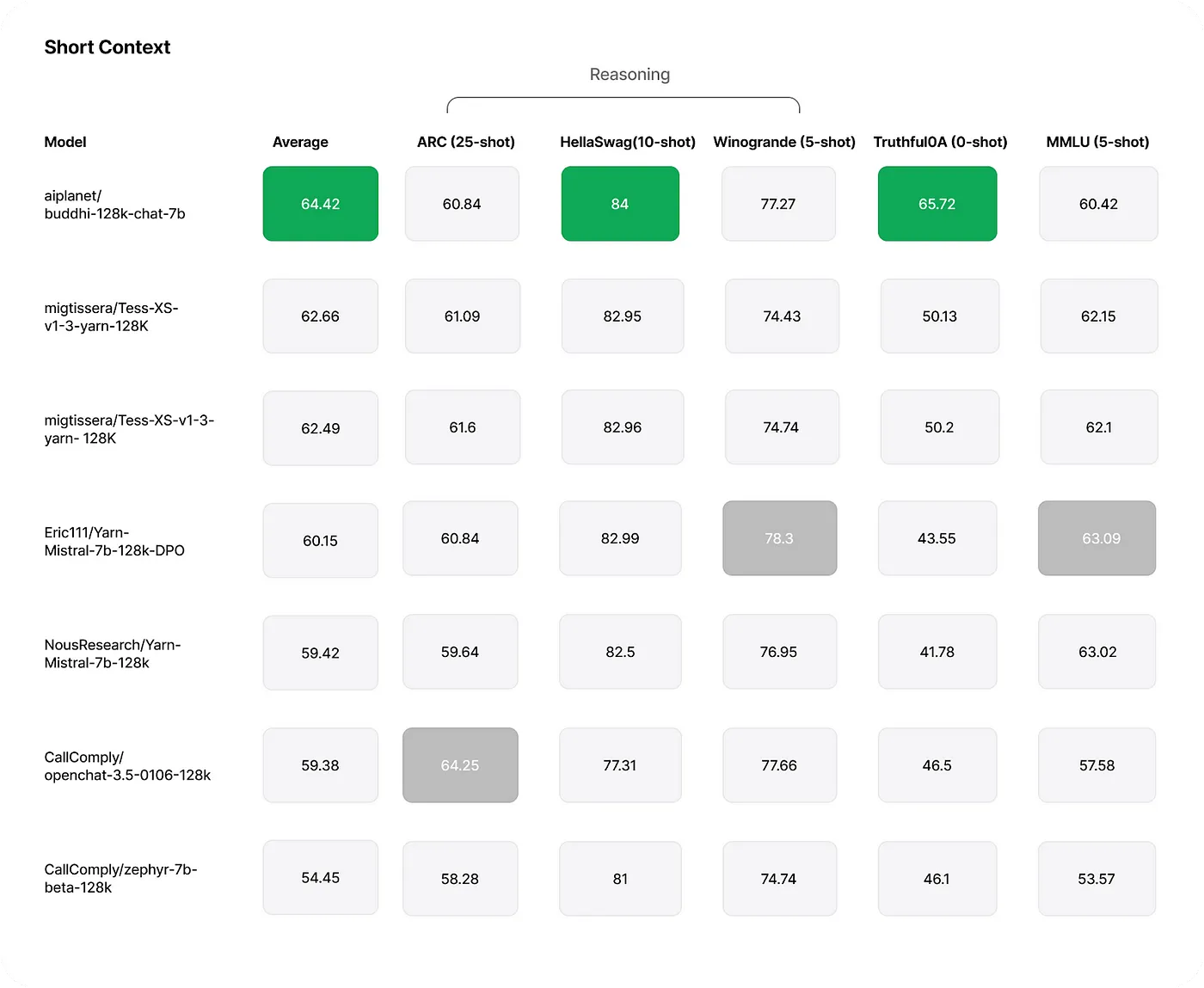 Source: Internet
Source: Internet
Long Context Benchmarks: Evaluations on datasets such as Banking77 have demonstrated the model’s capability to handle extensive context effectively.
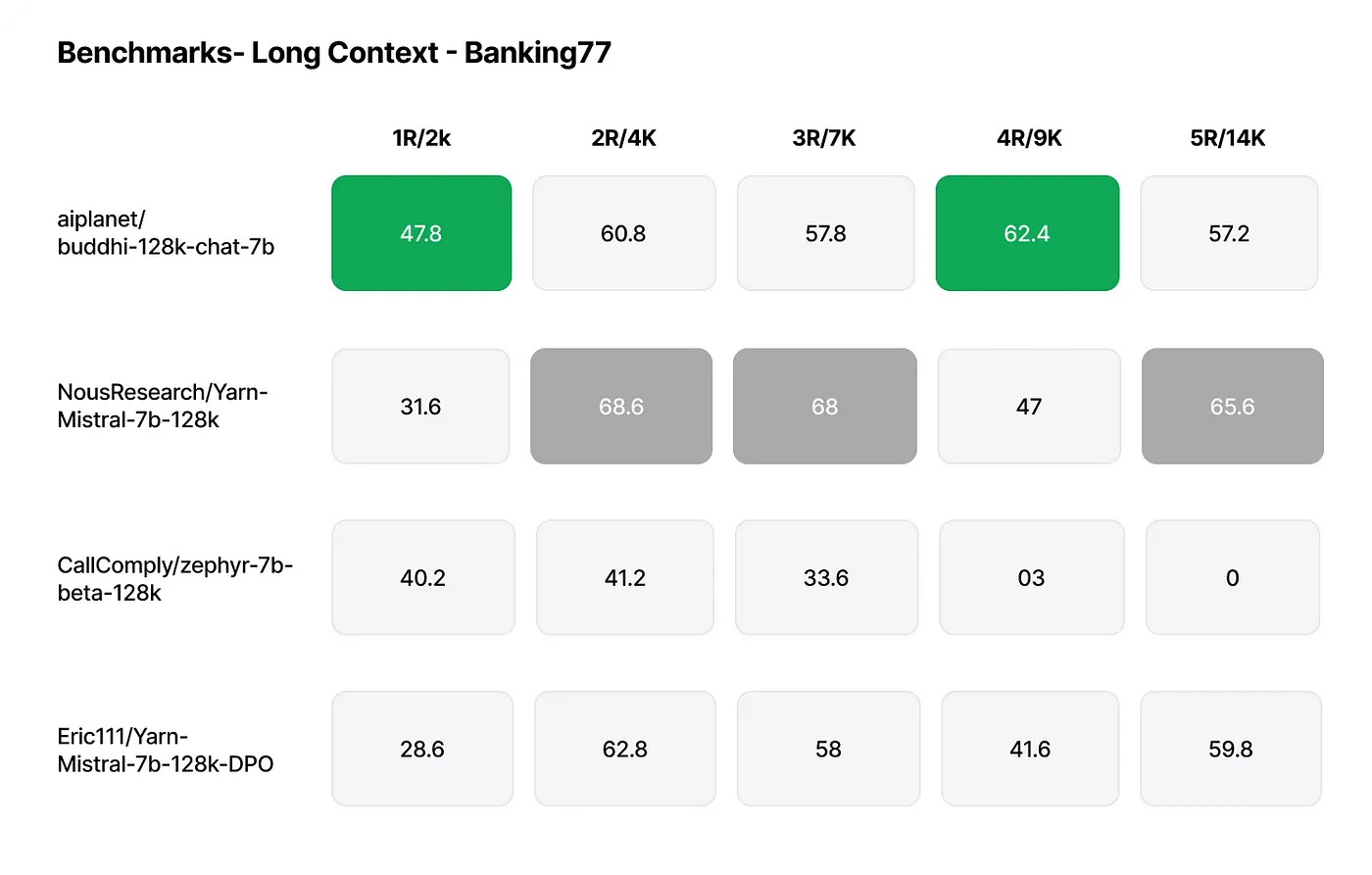 Source: Internet
Source: Internet
These benchmarks indicate that Buddhi-128K-Chat-7B matches or surpasses other models in its size class, particularly in handling long-context scenarios.
Inference and Hardware Requirements
To utilize the full 128K context length, the following hardware specifications are recommended:
- 128K Context Length: Requires 80GB VRAM, with A100 GPUs preferred.
- 32K Context Length: Requires 40GB VRAM, with A100 GPUs preferred.
 Source: Internet
Source: Internet
For optimized inference, integrating vLLM, which employs Paged Attention to reduce memory footprint, is advisable. Additionally, bitsandbytes quantization can enable the model to run on GPUs with lower VRAM, such as T4 GPUs.
Use Cases and Applications
The extended context window of Buddhi-128K-Chat-7B unlocks several practical applications:
- Enhanced Memory and Recall: The model can reference earlier parts of a conversation, leading to more coherent and natural dialogues.
- Accurate Instruction Following: Capable of retaining and executing multi-step instructions without missing details.
- Efficient Workflow Automation: Suitable for processing large datasets in fields like legal document review and medical records analysis.
- Improved Coherence in Text Generation: Able to generate long-form content without losing context, ensuring consistency throughout the text.
- Deep Analysis and Insight Generation: Facilitates comprehensive analysis in research-intensive fields by understanding extensive documents in a single pass.
While Buddhi-128K-Chat-7B offers significant advancements, it also presents challenges such as increased computational requirements and potential latency issues. Ongoing research and development are expected to address these limitations, further enhancing the model’s efficiency and accessibility.
Conclusion
In conclusion, Buddhi-128K-Chat-7B represents a notable step forward in open-source chat models, offering an extended context window that enhances its applicability across various domains requiring deep contextual understanding.