Efficient Fine-Tuning of Large Language Models: A Deep Dive into LoRA and QLoRA
In the era of large language models (LLMs) like GPT-3 and Llama, fine-tuning these behemoths for specific tasks has become a cornerstone of AI development. However, traditional full fine-tuning demands enormous computational resources, often requiring hundreds of GBs of GPU memory and extensive training time. This is where parameter-efficient fine-tuning (PEFT) techniques shine, allowing us to adapt massive models with minimal overhead. Among these, Low-Rank Adaptation (LoRA) and its quantized variant, Quantized LoRA (QLoRA), stand out for their efficiency and effectiveness. In this technical blog, we’ll explore the mechanics, mathematics, advantages, and practical implementations of LoRA and QLoRA, drawing from foundational research and real-world applications.
Understanding Fine-Tuning Challenges
Full fine-tuning involves updating all parameters of a pre-trained model on a downstream dataset, which maximizes performance but at a steep cost. For instance, fine-tuning a 175B-parameter model like GPT-3 requires retraining every weight, leading to high memory usage and deployment challenges. PEFT methods mitigate this by updating only a subset of parameters or adding lightweight adapters, reducing trainable parameters by orders of magnitude while preserving model quality.
 Source: Internet
Source: Internet
What is LoRA?
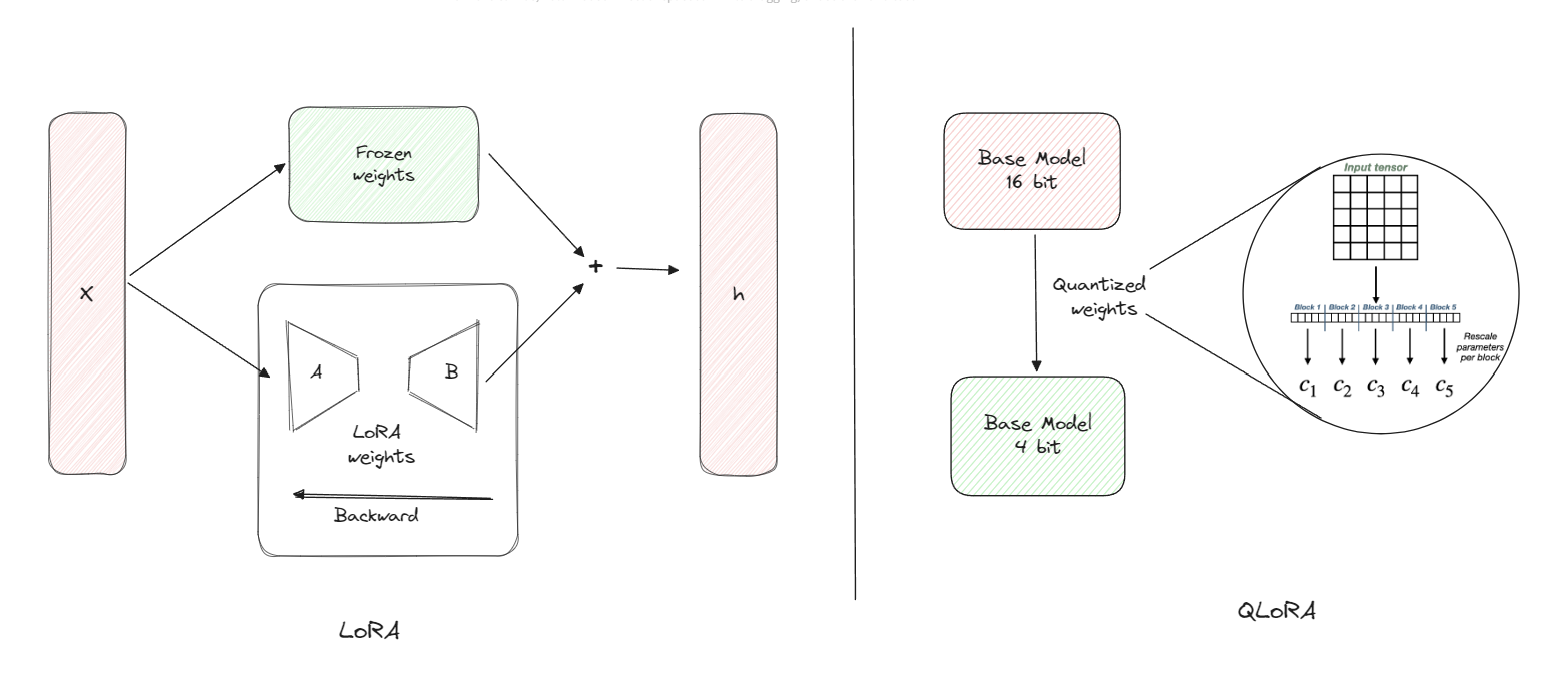
LoRA, or Low-Rank Adaptation, was introduced by Microsoft researchers in 2021 as a method to fine-tune LLMs by injecting low-rank trainable matrices into the model’s layers without altering the original weights. The core idea stems from the observation that weight updates during fine-tuning often lie in a low-dimensional subspace—meaning the changes to the model’s weights have a low “intrinsic rank.” Instead of updating the full weight matrix, LoRA decomposes these updates into smaller, low-rank factors.
How LoRA Works
Consider a pre-trained weight matrix \( W_0 \in \mathbb{R}^{d \times k} \) in a Transformer layer (e.g., attention weights like \( W_q, W_k, W_v, W_o \)). During fine-tuning, the update is constrained as \( \Delta W = BA \), where \( B \in \mathbb{R}^{d \times r} \), \( A \in \mathbb{R}^{r \times k} \), and \( r \ll \min(d, k) \) is the rank (typically 1-64). The original weights \( W_0 \) remain frozen, and only \( A \) and \( B \) are trained.
The forward pass becomes: \[ h = W_0 x + \frac{\alpha}{r} BA x \] where \( \alpha \) is a scaling factor (often set to twice the rank for stability), and the division by \( r \) normalizes the update magnitude. Initialization is key: \( A \) starts with random Gaussian values, while \( B \) is zeroed to ensure no initial change.
LoRA is typically applied to attention layers in Transformers, as empirical studies show this yields the best results with fewer parameters. For a model like GPT-3 175B, this reduces trainable parameters from billions to just thousands (e.g., 0.3M for r=8), slashing GPU memory needs by 3x and trainable parameters by 10,000x compared to full fine-tuning.
Advantages of LoRA
- Efficiency: Training throughput increases due to fewer gradients and optimizer states. For example, on GPT-3, LoRA matches or exceeds full fine-tuning quality on benchmarks like RoBERTa and DeBERTa while using far less memory.
- Deployment Flexibility: Post-training, \( BA \) can be merged into \( W_0 \), incurring no inference latency. Multiple LoRA adapters can share the base model, enabling quick task-switching.
- Hyperparameter Tips: Common ranks are 4-32; alpha is often 2x rank. Libraries like Hugging Face’s PEFT make integration seamless.
Introducing QLoRA: Quantization Meets LoRA
While LoRA is efficient, fine-tuning still requires loading the full model in high-precision formats (e.g., FP16), which can exceed single-GPU limits for models over 30B parameters. QLoRA, proposed in 2023, extends LoRA by quantizing the base model to 4 bits, enabling fine-tuning of 65B+ models on a single 48GB GPU without performance loss.
How QLoRA Builds on LoRA
QLoRA freezes a 4-bit quantized version of the pre-trained model and backpropagates gradients through it into LoRA adapters. Key innovations include:
- 4-bit NormalFloat (NF4) Quantization: An information-theoretically optimal data type for normally distributed weights. Weights are normalized to [-1, 1] and quantized into bins with equal expected values from a N(0,1) distribution, avoiding outliers.
- Double Quantization: Quantizes the quantization constants themselves (e.g., to 8-bit), saving ~0.37 bits per parameter by reducing constants’ memory footprint.
- Paged Optimizers: Uses NVIDIA unified memory to page optimizer states to CPU RAM during spikes, preventing OOM errors.
Mathematically, for a linear layer:
Gradients are computed in BF16 for LoRA params (\( L_1, L_2 \)) only, while the quantized base remains frozen.
QLoRA matches 16-bit full fine-tuning on benchmarks like Vicuna, with models like Guanaco achieving 99.3% of ChatGPT’s performance after 24 hours on one GPU.
Advantages of QLoRA Over LoRA
- Memory Savings: Reduces footprint from >780GB to <48GB for 65B models, democratizing access.
- No Performance Trade-off: Unlike naive quantization, QLoRA preserves accuracy by fine-tuning adapters on high-quality data.
- Scalability: Enables fine-tuning on consumer hardware, with extensions like 8-bit integration in Hugging Face for even broader use.
Practical Implementation with Hugging Face
Hugging Face’s libraries (Transformers, PEFT, Diffusers) simplify LoRA/QLoRA usage. For LoRA fine-tuning of Stable Diffusion:
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe.unet.enable_lora(rank=4) # Enable LoRA with rank 4
# Train on dataset, then merge and infer
For QLoRA with Gemma:
from keras_nlp.models import GemmaLM
gemma_lm = GemmaLM.from_preset("gemma_2b_en")
gemma_lm.quantize("int8") # Quantize to 8-bit (extendable to 4-bit)
gemma_lm.backbone.enable_lora(rank=4)
# Fine-tune and evaluate
Recent tutorials emphasize dataset preparation and evaluation for vision-language models like QWEN2.5VL.
Applications and Case Studies
LoRA/QLoRA power domain-specific adaptations, from chatbots (e.g., Guanaco) to image generation (e.g., Pokémon fine-tuning). In production, they’ve enabled zero-shot learning via hypernetworks and optimized LLMs for edge devices. Studies from Lightning AI show QLoRA excelling in memory-constrained environments across hundreds of experiments.
Conclusion
LoRA and QLoRA revolutionize LLM fine-tuning by making it accessible, efficient, and scalable. LoRA’s low-rank decomposition minimizes parameters, while QLoRA’s quantization pushes boundaries further, enabling massive models on modest hardware. As AI evolves, these techniques will be pivotal for customizing foundation models. Experiment with Hugging Face tools to harness their power in your projects.