Enhancing Natural Language Processing with Retrieval-Augmented Generation
Natural Language Processing (NLP) has witnessed remarkable advancements in recent years, with the advent of sophisticated language models like GPT-3 (Generative Pre-trained Transformer 3). However, one of the challenges that still persists in NLP is the generation of coherent and contextually relevant content. Retrieval-Augmented Generation (RAG) emerges as a powerful solution to address this issue, combining the strengths of both retrieval-based and generation-based approaches.
Understanding Retrieval-Augmented Generation
Retrieval-Augmented Generation is a hybrid approach that integrates the benefits of information retrieval systems with generative models. Let’s delve into the mathematical formulations of the key components of RAG.
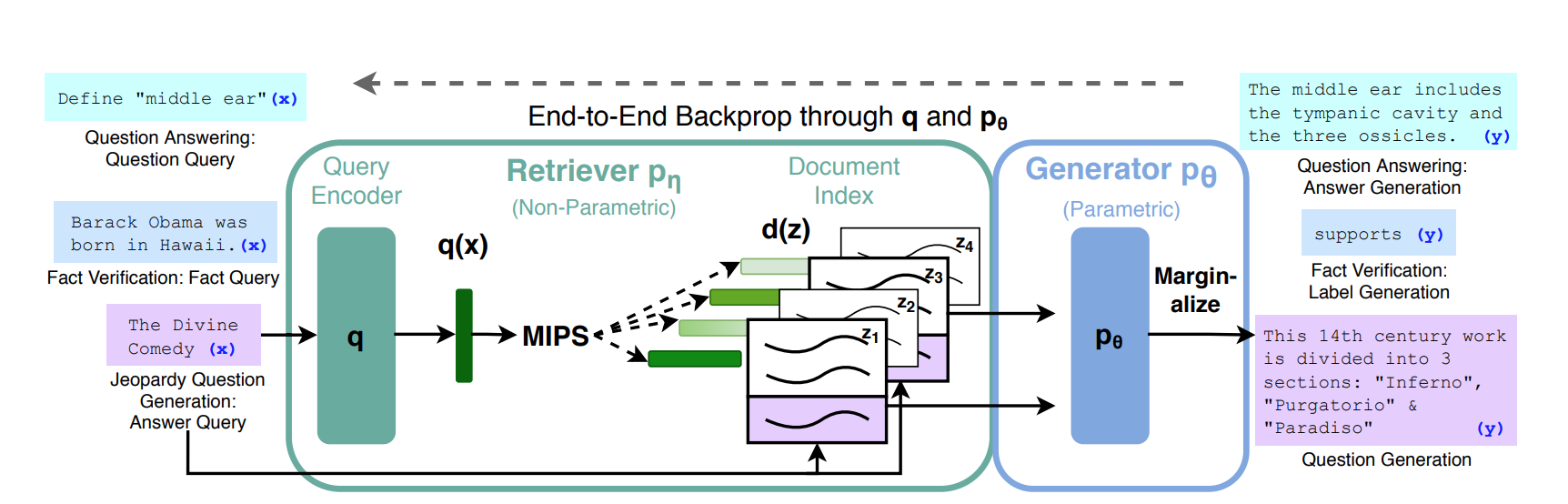 Figure: Overview of our approach. We combine a pre-trained retriever (Query Encoder + Document Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query \(x\), we use Maximum Inner Product Search (MIPS) to find the top-\(K\) documents \(z_i\). For the final prediction \(y\), we treat \(z\) as a latent variable and marginalize over seq2seq predictions given different documents. Source: arxiv.org
Figure: Overview of our approach. We combine a pre-trained retriever (Query Encoder + Document Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query \(x\), we use Maximum Inner Product Search (MIPS) to find the top-\(K\) documents \(z_i\). For the final prediction \(y\), we treat \(z\) as a latent variable and marginalize over seq2seq predictions given different documents. Source: arxiv.org
1. Generative Model
The generative model in RAG is often based on a pre-trained transformer architecture, such as GPT-3. The core functionality involves generating text given a context. Mathematically, the generative model can be represented as:
2. Retrieval Model
The retrieval model is responsible for fetching relevant information from a knowledge base. This can be achieved through techniques like dense retrieval using embeddings. The retrieval model computes the similarity between the input query and the documents in the knowledge base. Mathematically, this can be expressed as:
where \( Q \) is the query, \( \text{KnowledgeBase} \) is the set of documents, \( d \) represents a document, \( \text{Embed}(\cdot) \) denotes the embedding function, and \( \text{similarity}(\cdot) \) measures the similarity between the query and document embeddings.
3. Indexing Mechanism
Indexing mechanisms play a crucial role in efficiently retrieving information. Commonly, techniques like approximate nearest neighbors are employed. Mathematically, indexing involves mapping documents to a space such that retrieval operations are expedited. This can be represented as:
4. Context-Aware Integration
To integrate retrieved information into the generative process while maintaining context, the retrieval model output needs to be combined with the generative model’s output. A simple formulation for context-aware integration can be:
Advantages of Retrieval-Augmented Generation
Improved Relevance: By integrating information retrieval, RAG ensures that the generated content is contextually relevant and grounded in factual accuracy. This is particularly beneficial in applications where precision and relevance are critical, such as question-answering systems.
Addressing Data Sparsity: In scenarios where training data is limited, RAG can leverage external knowledge bases to compensate for the lack of specific information. This makes the model more robust and capable of handling a broader range of topics.
Contextual Enrichment: The retrieval-augmented approach allows for the enrichment of generated content by pulling in relevant details from a diverse set of sources. This not only enhances the quality of the generated text but also broadens the scope of information covered.
Reduced Ambiguity: Integrating retrieval mechanisms helps in disambiguating the meaning of ambiguous terms or phrases by pulling in contextually appropriate information from the knowledge base.
Applications of Retrieval-Augmented Generation
Question Answering Systems: RAG is particularly effective in question-answering systems where precise and contextually relevant answers are essential. The retrieval model can fetch information from a knowledge base to support or augment the generative model’s response.
Content Creation: In content creation tasks, such as article writing or summarization, RAG can enhance the coherence and factual accuracy of the generated content by pulling in information from external sources.
Dialog Systems: Conversational agents can benefit from RAG by providing more informative and contextually relevant responses. The retrieval model aids in quickly accessing relevant information to support the generative model’s output during a conversation.
Challenges and Future Directions
While Retrieval-Augmented Generation shows great promise, it is not without its challenges. Fine-tuning the balance between the generative and retrieval components, handling diverse knowledge bases, and addressing potential biases in retrieved information are areas that require further research. Additionally, exploring ways to dynamically update the knowledge base during the generative process could open new possibilities for real-time applications.
In conclusion, Retrieval-Augmented Generation represents a significant step forward in enhancing the capabilities of natural language processing systems. By seamlessly integrating the strengths of generative and retrieval models, RAG holds the potential to revolutionize various NLP applications, making them more accurate, contextually aware, and capable of handling a wide range of tasks. As research in this field continues to progress, we can expect even more sophisticated and versatile language models that leverage the best of both worlds.