From Text to Tokens: The Complete Guide to Tokenization in LLMs
In the ever-evolving field of artificial intelligence, large language models (LLMs) like GPT-4, Claude, Gemini, and LLaMA have reshaped how machines understand and generate human language. Behind the impressive capabilities of these models lies a deceptively simple but foundational step: tokenization.
In this blog, we will dive deep into the concept of tokenization, understand its types, why it’s needed, the challenges it solves, how it works under the hood, and where it’s headed in the future. This is a one-stop technical deep-dive for anyone looking to fully grasp the backbone of language understanding in LLMs.
What is Tokenization?
At its core, tokenization is the process of converting raw text into smaller units called tokens that a language model can understand and process. These tokens can be:
- Characters
- Words
- Subwords
- Byte-pair sequences
- WordPieces
- SentencePieces
- Byte-level representations
Each model has its own strategy, depending on design goals like efficiency, vocabulary size, multilingual handling, and memory constraints.
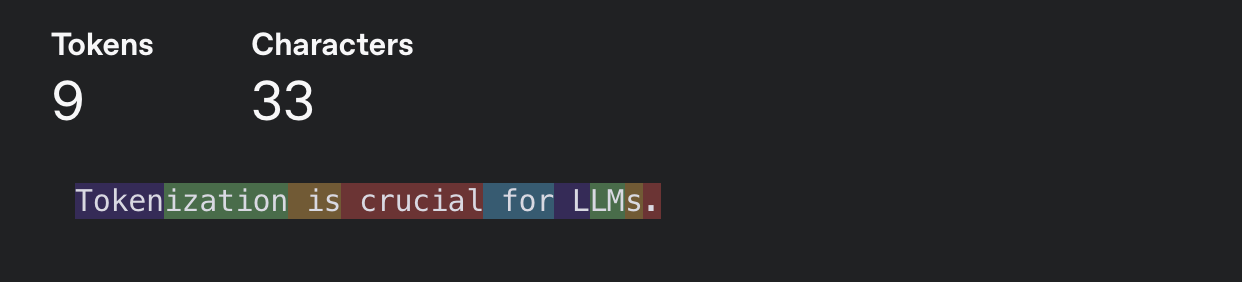
For example, the sentence:
"Tokenization is crucial for LLMs."May be tokenized as:
- Word-level:
["Tokenization", "is", "crucial", "for", "LLMs", "."] - Character-level:
["T", "o", "k", ..., "L", "L", "M", "s", "."] - Subword (BPE):
["Token", "ization", "is", "cru", "cial", "for", "LL", "Ms", "."]
Tokens
Token IDs

Why Tokenization is Needed in LLMs
Language models operate over numbers (tensors), not raw strings. Before any neural network processes your prompt, the words must be:
- Split into atomic units (tokens)
- Mapped to numerical IDs (vocabulary embedding)
- Fed into the model as vectors
Without tokenization:
- Models would struggle with infinite vocabulary.
- Multilingual text and compound words would explode the vocabulary.
- There would be no efficient way to control sequence length or positional encoding.
Types of Tokenization Strategies
Word-Level Tokenization
Each word is a token. Simple but inefficient for:
- Unknown words (out-of-vocabulary issues)
- Morphologically rich languages
- Compound words
Example: “unhappiness” → 1 token → [“unhappiness”] If unseen during training, this is a problem.
Character-Level Tokenization
Each character is a token. Solves OOV issues but leads to longer sequences and loss of semantic granularity.
Example: “unhappiness” → [“u”, “n”, “h”, “a”, “p”, …]
Subword Tokenization
Breaks words into frequent subword units using statistical techniques like:
- Byte Pair Encoding (BPE) – used by GPT-2, GPT-3
- WordPiece – used by BERT
- Unigram Language Model – used by SentencePiece (T5, LLaMA)
Example (BPE): “unhappiness” → [“un”, “happi”, “ness”]
Benefits:
- Handles unknown words gracefully
- Reduces vocabulary size
- Efficient for multilingual models
Byte-Level Tokenization
Tokenizes text at the byte level, including UTF-8 encodings.
Used by models like GPT-3.5/4 to handle raw binary inputs and emojis robustly.
Example: “🔥” → byte sequence → [240, 159, 148, 165]
SentencePiece
A library that trains subword models using BPE or Unigram LM on raw text. Used in multilingual LLMs like T5, mT5.
It allows training on raw text without pre-tokenization (no need for whitespace-based splitting).
How Tokenization Works: Under the Hood
Training a Tokenizer
During tokenizer training, the process involves:
- Reading a large corpus
- Building frequency tables of substrings
- Iteratively merging the most frequent substrings
- Forming a vocabulary of tokens
- Saving a tokenizer model (vocab + merge rules)
Encoding
At inference or training:
- Input string → split into substrings based on learned merges
- Tokens → mapped to numerical IDs via the vocabulary
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokens = tokenizer.tokenize("Tokenization is powerful.")
print(tokens)
# Output: ['Token', 'ization', 'Ġis', 'Ġpowerful', '.']
Ġ indicates a space in GPT-2 tokenizers.
Tokenization and Model Limits
Most LLMs have a context window defined in tokens, not characters. For instance:
- GPT-3.5: 4,096 tokens
- GPT-4 (o4): 128,000 tokens
- Claude 3 Opus: \~200,000 tokens
So, 1000 words of English ≈ 750 tokens.
This is crucial for prompt design, summarization, RAG (Retrieval Augmented Generation), and efficient inference.
Challenges and Trade-offs
| Challenge | Description |
|---|---|
| OOV (Out-of-Vocabulary) | Especially for word-level tokenization |
| Token inflation | Some languages (e.g., Chinese, Japanese) produce more tokens |
| Inconsistency | Subword boundaries may not align with morphemes |
| Efficiency vs Accuracy | Smaller tokens = longer sequences = more compute |
| Encoding Bias | Tokenizers trained on certain scripts or corpora may underperform on others |
Tokenization in Multilingual and Code Models
Multilingual Tokenization
- Unicode-aware models must handle multiple scripts (Latin, Devanagari, Arabic, etc.)
- Token inflation can disadvantage languages like Hindi and Tamil
- SentencePiece helps standardize across languages
Code Tokenization
- Code models (e.g., Codex, CodeBERT) often use language-specific tokenizers
- Must preserve syntax, spacing, indentation, and even comments
Example:
def say_hello():
print("Hello")
→ [‘def’, ‘Ġsay’, ‘_’, ‘hello’, ‘()’, ‘:’, ‘Ġ’, ‘print’, ‘(”, ‘Hello’, ‘”)’]
Compression, Prompt Engineering, and Token Optimization
Tokenization also directly affects:
- Prompt length limits (compressed prompts → more room for data)
- Token cost in inference/billing
- RAG performance (chunking based on tokens)
- Training data deduplication (token-based hashing)
Optimizing prompts for fewer tokens can reduce cost and latency.
Tokenization vs. Embeddings
It’s important to note:
- Tokenization comes before embedding.
- Token → token ID → embedding vector
A poor tokenization scheme = noisy embeddings = reduced model performance.
The Future of Tokenization in LLMs
Token-Free Models
Efforts like Charformer and Byte-level transformers aim to bypass static tokenization and learn from raw bytes or characters.
Neural Tokenization
Trainable tokenizers using neural nets to learn optimal segmentation dynamically.
Universal Tokenizers
Tokenizers trained across modalities (text, image, code) using a common vocabulary to unify multimodal models.
Efficient Context Windows
With sliding-window and compression-based methods (e.g., Mamba, Hyena), token overhead may reduce for long contexts.
Major LLMs and Their Tokenization
Model Tokenizers
| Model | Tokenizer | Type | Notes |
|---|---|---|---|
| GPT-3/4 | GPT2Tokenizer | BPE + byte | Handles Unicode well |
| BERT | WordPiece | Subword | Requires pre-tokenization |
| RoBERTa | BPE (FairSeq) | Subword | Custom vocabulary |
| T5 | SentencePiece | Unigram LM | Whitespace-free tokenization |
| LLaMA 2/3/4 | SentencePiece | Unigram LM | Supports multiple languages |
| Claude | Byte-level BPE | Proprietary | Handles emojis and long context |
Conclusion
Tokenization may appear trivial at first glance, but it’s the hidden workhorse powering the language capabilities of every modern LLM. From enabling multilingual understanding to compressing long documents into tight prompts, tokenization determines what the model sees, learns, and generates.
As we step into an era of 1M+ token context windows, modality fusion, and instruction-following agents, tokenization will either evolve or be replaced by more fluid, learned representations.
But for now—and the foreseeable future—it remains a vital piece of the LLM puzzle.