Smartcase Engine: A Modern Framework for Intelligent Case Management
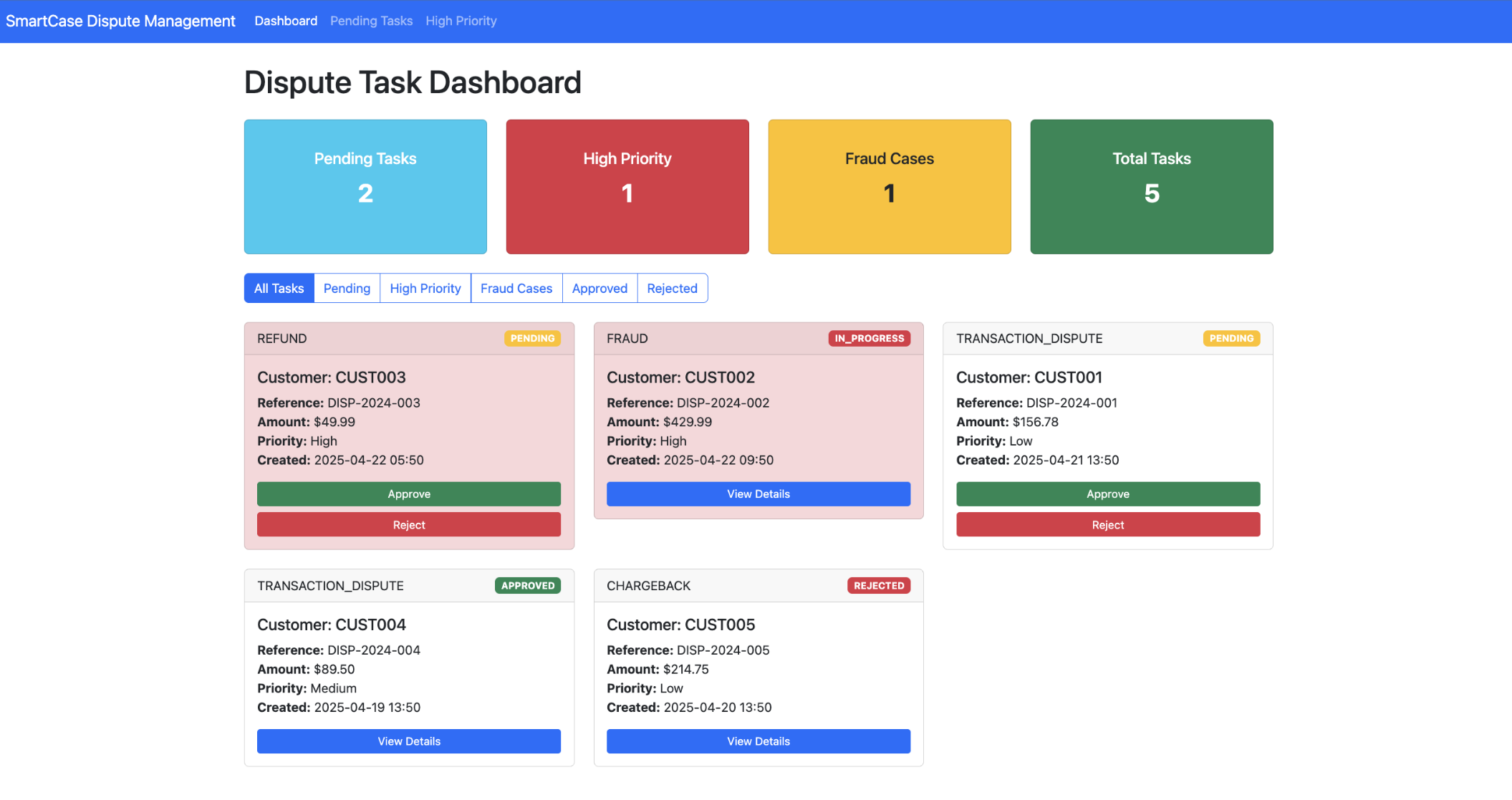
In today’s dynamic business environment, efficient case management is paramount. Enter Smartcase Engine, an advanced case management framework designed to streamline complex case handling through real-time tracking, efficient workflows, and automated decision-making processes.
What is Smartcase Engine?
Smartcase Engine is a modular, microservices-based platform tailored for managing intricate case workflows. It offers:
- Real-Time Case Tracking: Monitor cases as they progress through various stages.
- Efficient Workflows: Automate and optimize the sequence of tasks involved in case resolution.
- Automated Decision-Making: Leverage predefined rules and AI to make informed decisions without manual intervention.
 Source: Rishijeet Mishra’s Blog
Source: Rishijeet Mishra’s Blog
Deep Dive: Smartcase Engine Architecture
At the heart of Smartcase Engine is a clean, extensible microservices-based architecture designed to support complex workflows in case/dispute management scenarios. The system is broken into discrete services that communicate via REST APIs and Kafka for event-driven interactions. This modular approach allows teams to scale and evolve components independently.
Let’s explore the core services that power this engine:
Dispute Intake Service
Purpose: This is the gateway to the system — the service responsible for accepting new cases or disputes.
Responsibilities:
- Receive new dispute cases via API or event (Kafka).
- Validate and enrich the incoming payload.
- Generate a unique dispute ID.
- Store initial metadata and emit an event to kick off downstream workflow.
Technical Highlights:
- Built using Java + Quarkus for lightweight runtime.
- Connects to Kafka for emitting intake-completed events.
- Persists initial data in a database (e.g., PostgreSQL or any pluggable DB).
- Implements REST endpoints for manual intake testing or system integration.
Why it matters: This service ensures that all disputes entering the system are properly structured and immediately traceable — forming the root of all subsequent orchestration.
Dispute Workflow Service
Purpose: This is the brain of the engine, orchestrating the lifecycle of a dispute across multiple business stages.
Responsibilities:
- Define and manage the state machine (or BPMN-style flow) for a dispute.
- Trigger actions based on status updates (e.g., escalate, resolve, pause).
- Call external services when required (e.g., fetch additional metadata, update agent queue).
- Track state transitions and support retries/failures.
Technical Highlights:
- Uses a stateless orchestration model.
- Integration with Kafka allows event-driven step progression.
- Could be integrated with BPMN engines (like Camunda or Flowable) for visual modeling.
Why it matters: This is the system’s core engine. It allows Smartcase to define complex, non-linear workflows without hardcoding logic into the intake or agent UI layers.
Dispute Classification Service
Purpose: Adds intelligence to the process by classifying disputes into appropriate categories.
Responsibilities:
- Use business rules or ML models to assign dispute types (e.g., “billing error”, “fraud”, “product defect”).
- Optionally flag high-risk or high-priority disputes.
- Feed classification results back into the workflow service to route the case accordingly.
Technical Highlights:
- Stateless classification service.
- Integrates with a basic rule engine or external ML service (could be backed by Python/ONNX, or a local inference server).
- Input: structured dispute metadata. Output: classification code or tag.
Why it matters: Classification drives automation. By programmatically tagging and triaging disputes, Smartcase avoids human bottlenecks and supports intelligent queue assignment.
Agent UI Service
Purpose: The interface between human agents and the system.
Responsibilities:
- Display dispute data and current status.
- Allow agents to take actions (e.g., approve, reject, escalate).
- Show workflow progression.
- Track comments, attachments, and communication logs.
Technical Highlights:
- Frontend (typically in React or Angular).
- Backend proxy or BFF layer in Quarkus serving data via REST.
- Authenticated access with role-based views (agent, supervisor, auditor).
- Pagination, search, filters, and sort capabilities to handle large volumes.
Why it matters: No matter how automated the backend is, disputes often need human judgment. This UI is purpose-built for efficiency and transparency in resolution workflows.
Dispute Common Module
Purpose: A shared library of core utilities and contracts.
Responsibilities:
- Define POJOs (Plain Old Java Objects) and DTOs (Data Transfer Objects).
- Common validation logic.
- Central configuration definitions.
- Shared Kafka event schema.
- Error handling standards and API response models.
Technical Highlights:
- Packaged as a reusable JAR.
- Imported by all services as a dependency.
- Promotes DRY principles and API consistency.
Why it matters: Microservices need to stay loosely coupled — but shared types and utilities must remain consistent. This module enforces a standard language across the ecosystem.
Optional Add-ons (Future Ready)
Depending on your scale and use case, Smartcase Engine can be extended with:
- Notification Service: For sending SMS/email alerts to users or agents.
- Audit Logging: For compliance with financial or legal audits.
- Retry/Dead-letter Queue Mechanism: To gracefully handle transient failures.
- Observability Tools: Integrated with Prometheus, Grafana, and OpenTelemetry for distributed tracing.
Deployment and Setup
Smartcase Engine is containerized using Docker, facilitating seamless deployment. Key scripts and configurations include:
- Dockerfile: Defines the environment for each microservice.
- docker-compose.yml: Orchestrates multi-container deployments for local development and testing.
- build-and-deploy.sh: Automates the build and deployment process.
- start-services.sh: Initiates all services concurrently.
To get started:
git clone https://github.com/rishijeet/smartcase-engine.git
cd smartcase-engine
chmod +x build-and-deploy.sh start-services.sh
./build-and-deploy.sh
./start-services.sh
Testing and Validation
Each microservice includes unit and integration tests to ensure reliability. The modular design allows for isolated testing, simplifying debugging and maintenance.
Potential Use Cases
Smartcase Engine’s versatility makes it suitable for various domains:
- Financial Services: Automating dispute resolutions in banking and insurance.
- Customer Support: Managing customer complaints and service requests.
- Legal Case Management: Tracking legal cases, evidence, and proceedings.
- Healthcare: Handling patient grievances and administrative cases.
Contributing to Smartcase Engine
The project welcomes contributions from the developer community. To contribute:
- Fork the repository.
- Create a new branch for your feature or bugfix.
- Ensure code quality by running existing tests and adding new ones if necessary.
- Submit a pull request with a clear description of your changes.
Further Reading
For more in-depth information:
Conclusion
Smartcase Engine exemplifies how modern architectural principles can be harnessed to build robust, scalable, and efficient case management systems. Whether you’re looking to streamline dispute resolutions or manage complex workflows, Smartcase Engine offers a solid foundation to build upon.