Supercharge Reasoning in AI: Hands-On Chain of Thought Builds
Chain of Thought (CoT) is a prompting technique introduced in a 2022 paper by Google researchers (Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”). The core idea is simple: instead of asking an LLM for a direct answer, you instruct it to reason step by step. This elicits better performance on tasks requiring logic, math, commonsense, or multi-step planning.
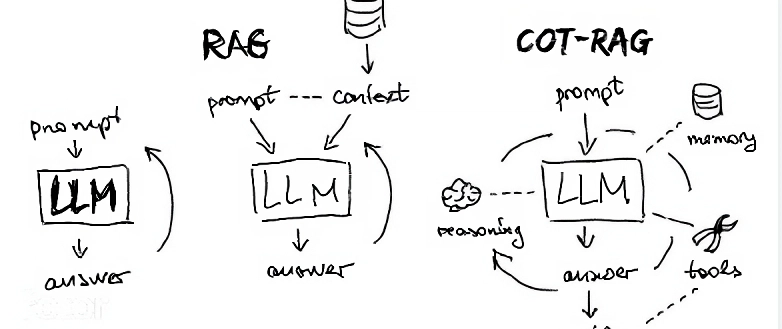 Source: Internet
Source: Internet
For example:
- Direct Prompt: “What is 15% of 200?”
- CoT Prompt: “What is 15% of 200? Let’s think step by step.”
The LLM might respond:
- “Step 1: 15% means 15 per 100, so 15/100 = 0.15.
- Step 2: Multiply by 200: 0.15 * 200 = 30. So, the answer is 30.”
This “thinking” process isn’t magic—it’s emergent from the model’s training on vast datasets where step-by-step explanations are common. CoT shines in zero-shot (no examples) or few-shot (with examples) scenarios, and variants like Tree of Thoughts or Self-Consistency build on it for even more robustness.
Why Does CoT Work?
- Decomposes Complexity: Breaks problems into manageable sub-steps, reducing error rates.
- Transparency: Users see the “thought process,” building trust and allowing debugging.
- Scalability: Works with any LLM API; no need for fine-tuning.
- Applications: Math solvers, code debuggers, decision-making tools, chatbots that explain reasoning.
Research shows CoT improves accuracy by 10-50% on benchmarks like GSM8K (math) or CommonsenseQA. In interactive apps, it can stream thoughts progressively, giving users a “processing” indicator.
Evolution and Variants of CoT
CoT has evolved rapidly:
- Zero-Shot CoT: Just add “Let’s think step by step” to the prompt.
- Few-Shot CoT: Provide 2-5 examples of step-by-step reasoning before the query.
- Automatic CoT: Use LLMs to generate CoT examples dynamically.
- Tree of Thoughts (ToT): Explores multiple reasoning paths like a tree search.
- Graph of Thoughts: Models reasoning as a graph for non-linear problems.
In 2025, with models like Grok 4, CoT is often combined with tools (e.g., code execution or web search) for agentic systems—AI agents that plan, act, and reflect.
Building a Chain of Thought Application: Step-by-Step Guide
To build a CoT application, we’ll create a Python-based tool that:
- Takes user input.
- Applies CoT prompting via an LLM API.
- Streams the response to show “thinking” in real-time (using API streaming features).
- Parses the final answer for clarity.
We’ll use OpenAI’s API as an example. Assumptions:
- You have an API key.
- Focus on a math/word problem solver, but extensible to any domain.
Step 1: Set Up Your Environment
Install required libraries:
pip install openai requests
Step 2: Basic CoT Implementation
Start with a simple non-streaming version. This script prompts the LLM with CoT and prints the full response.
import openai
# Set your API key
openai.api_key = "your-openai-api-key" # Replace with actual key
def cot_reasoning(query, model="gpt-4o"):
"""
Applies Chain of Thought prompting to a query.
Args:
- query (str): The user's question.
- model (str): LLM model to use.
Returns:
- str: The reasoned response.
"""
# CoT Prompt Template (Few-Shot for better results)
prompt = """
Solve the following problem step by step.
Example 1:
Question: If a car travels 60 miles in 1.5 hours, what is its speed?
Step 1: Speed is distance divided by time.
Step 2: Distance = 60 miles, Time = 1.5 hours.
Step 3: Speed = 60 / 1.5 = 40 mph.
Answer: 40 mph.
Example 2:
Question: What is the next number in the sequence: 2, 4, 8, 16?
Step 1: Observe the pattern: each number is doubled.
Step 2: 2 * 2 = 4, 4 * 2 = 8, 8 * 2 = 16.
Step 3: Next is 16 * 2 = 32.
Answer: 32.
Now, your question:
Question: {query}
"""
formatted_prompt = prompt.format(query=query)
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": formatted_prompt}]
)
return response.choices[0].message.content
# Usage
query = "What is 25% of 400?"
result = cot_reasoning(query)
print(result)
Expected Output:
Step 1: 25% means 25 per 100, so 0.25.
Step 2: Multiply by 400: 0.25 * 400 = 100.
Answer: 100.
This shows the “thinking” steps. To make it interactive, add a loop for multiple queries.
Step 3: Adding Real-Time Processing Feedback
To “let you know that it is processing these steps,” use streaming. OpenAI supports response streaming, printing tokens as they arrive—simulating thinking.
Modify the function:
import openai
import sys
openai.api_key = "your-openai-api-key"
def cot_streaming_reasoning(query, model="gpt-4o"):
"""
Streams Chain of Thought reasoning in real-time.
"""
prompt = """
Solve the following problem step by step. Think out loud.
# Few-shot examples here (same as above)
Question: {query}
"""
formatted_prompt = prompt.format(query=query)
stream = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": formatted_prompt}],
stream=True # Enable streaming
)
print("Thinking...")
full_response = ""
for chunk in stream:
if chunk.choices[0].delta.get("content"):
content = chunk.choices[0].delta.content
sys.stdout.write(content) # Print incrementally
sys.stdout.flush()
full_response += content
print("\nDone!")
return full_response
# Usage
query = "If I have 3 apples and eat 2, how many are left?"
cot_streaming_reasoning(query)
How It Works:
- The
stream=Trueparameter yields partial responses. - We print each chunk, showing steps like “Step 1: …” as they generate.
- This creates a “processing” effect—users see thoughts unfolding.
For a web app, use Flask or Streamlit to stream via WebSockets.
Step 4: Advanced Features – Parsing and Error Handling
To extract the final answer reliably, parse the response. Add self-consistency by generating multiple CoTs and voting.
def parse_final_answer(response):
"""
Extracts the final answer from CoT response.
"""
lines = response.split("\n")
for line in reversed(lines):
if line.startswith("Answer:"):
return line.split("Answer:")[1].strip()
return "No clear answer found."
# In your main function:
result = cot_streaming_reasoning(query)
final_answer = parse_final_answer(result)
print(f"Final Answer: {final_answer}")
For robustness (Self-Consistency CoT):
- Run 3-5 CoT generations.
- Use majority vote on answers.
def self_consistent_cot(query, num_samples=3):
answers = []
for _ in range(num_samples):
response = cot_reasoning(query) # Or streaming version
answer = parse_final_answer(response)
answers.append(answer)
# Simple majority vote
from collections import Counter
most_common = Counter(answers).most_common(1)
return most_common[0][0] if most_common else "Inconsistent results"
# Usage
consistent_answer = self_consistent_cot("A bat and ball cost $1.10 total. The bat costs $1 more than the ball. How much is the ball?")
print(consistent_answer) # Should be $0.05
Step 5: Building a Full Application
For a complete app, use Streamlit for a UI:
import streamlit as st
import openai
openai.api_key = "your-openai-api-key"
st.title("Chain of Thought Reasoner")
query = st.text_input("Enter your question:")
if st.button("Reason"):
with st.spinner("Thinking step by step..."):
response = cot_streaming_reasoning(query) # Use non-streaming for simplicity, or adapt
st.write(response)
final = parse_final_answer(response)
st.success(f"Final Answer: {final}")
Run with streamlit run app.py. This creates a web interface where users input queries and see the CoT process.
Challenges and Best Practices
- Token Limits: CoT increases prompt length; use efficient models.
- Bias in Reasoning: LLMs can hallucinate steps—validate with tools (e.g., code execution for math).
- Customization: For domains like code generation, add “Step 1: Understand requirements. Step 2: Plan code structure.”
- Integration with Agents: Combine CoT with ReAct (Reason + Act) for tool-using agents.
- Ethics: Ensure transparency; CoT doesn’t make AI infallible.
Conclusion
Chain of Thought applications transform LLMs from black boxes into transparent reasoners. By building step-by-step processing into your prompts and code, you create tools that not only solve problems but explain how.