Understanding ReAct in Large Language Models
ReAct, short for Reasoning and Acting, is a paradigm for enhancing large language models (LLMs) by integrating verbal reasoning traces with task-specific actions. Introduced in a 2022 paper, it addresses limitations in chain-of-thought (CoT) prompting by allowing models to interact with external environments, such as APIs or databases, to gather real-time data. This makes LLMs more reliable for tasks requiring factual accuracy or multi-step planning.
In the evolving field of artificial intelligence, large language models (LLMs) have transformed how we approach problem-solving, but they often struggle with hallucinations—generating plausible but incorrect information—or handling tasks requiring real-world interaction. Enter ReAct (Reasoning and Acting), a prompting framework that synergizes reasoning traces with actionable steps, enabling LLMs to behave more like intelligent agents. This detailed blog explores ReAct’s foundations, mechanics, advantages, and practical implementation, culminating in a sample Python application using LangChain. We’ll draw on established research and code examples to provide a comprehensive guide, updated with insights as of 2025.
How ReAct Works
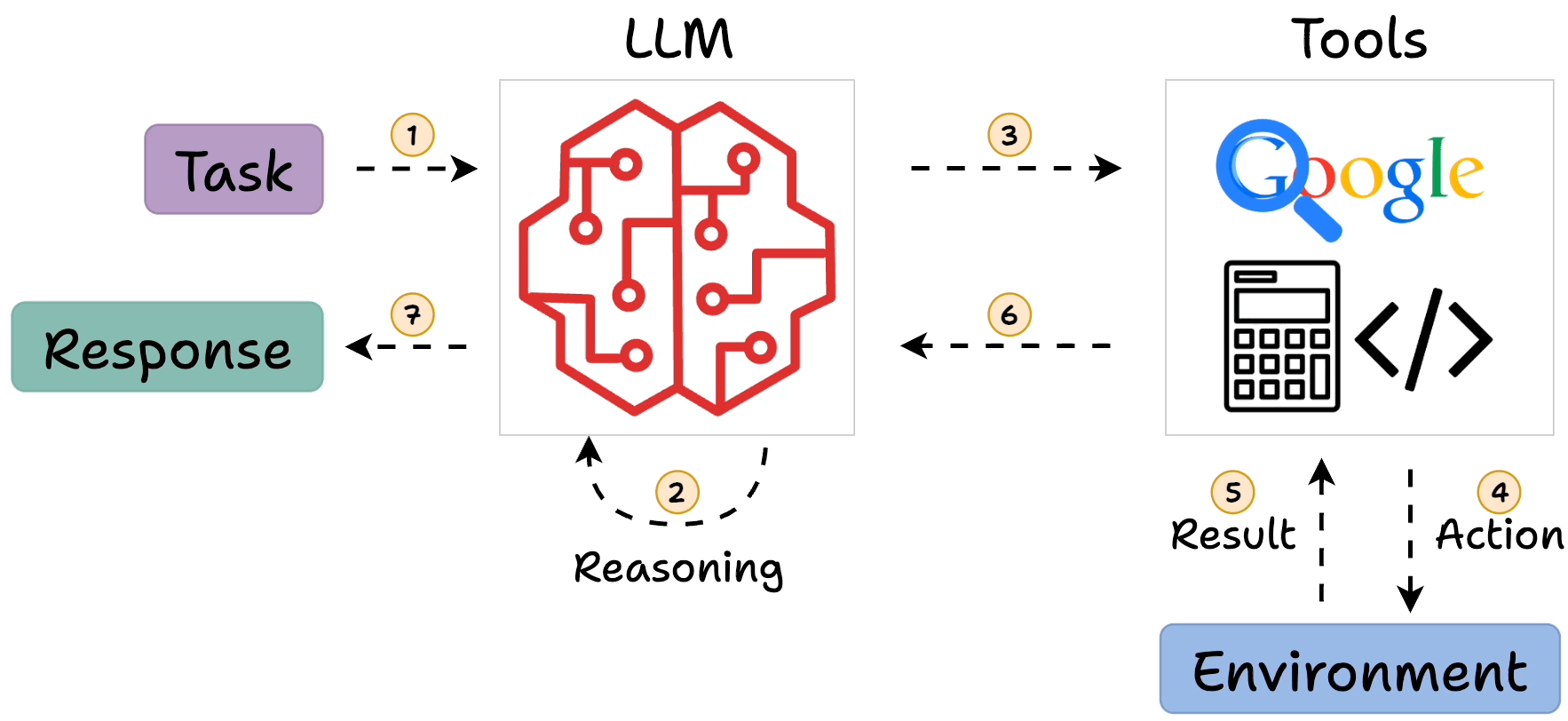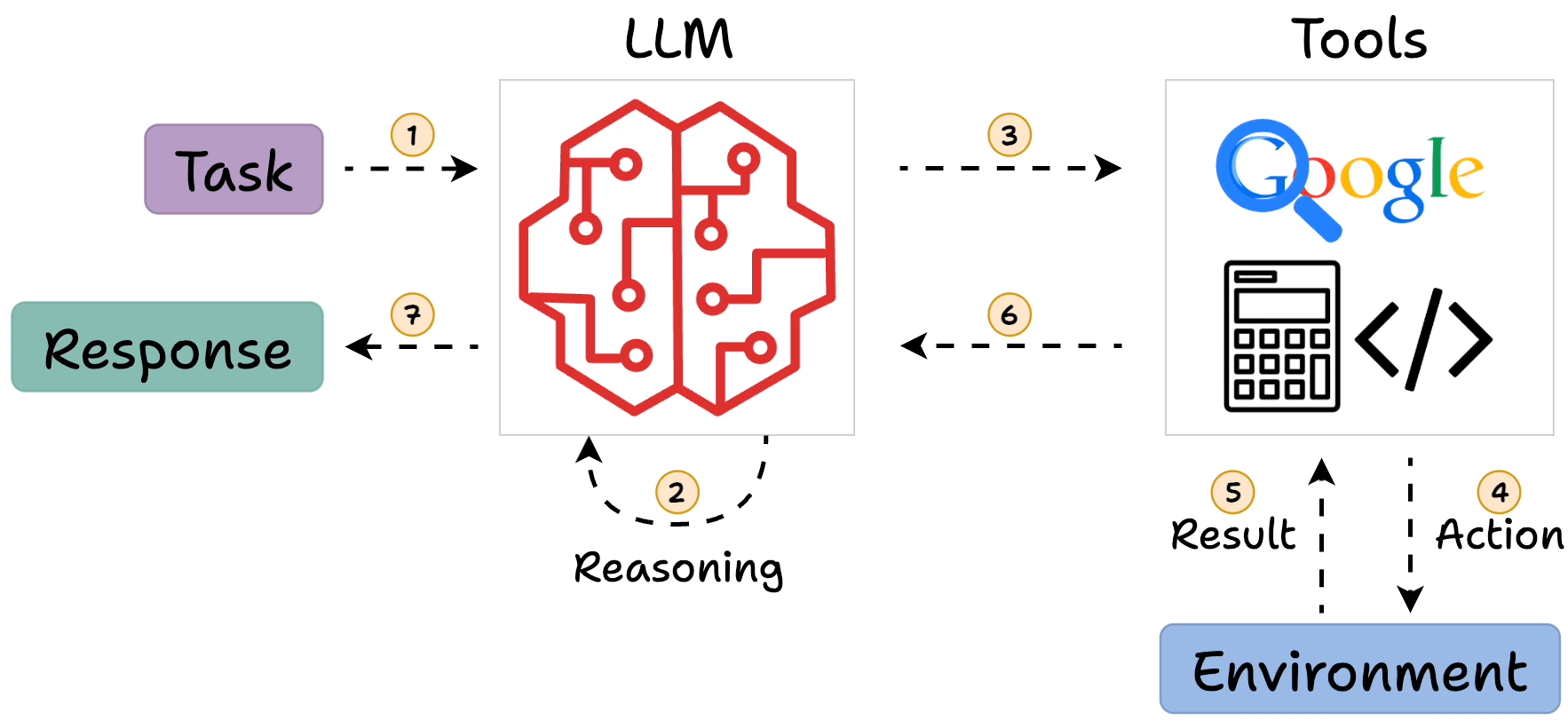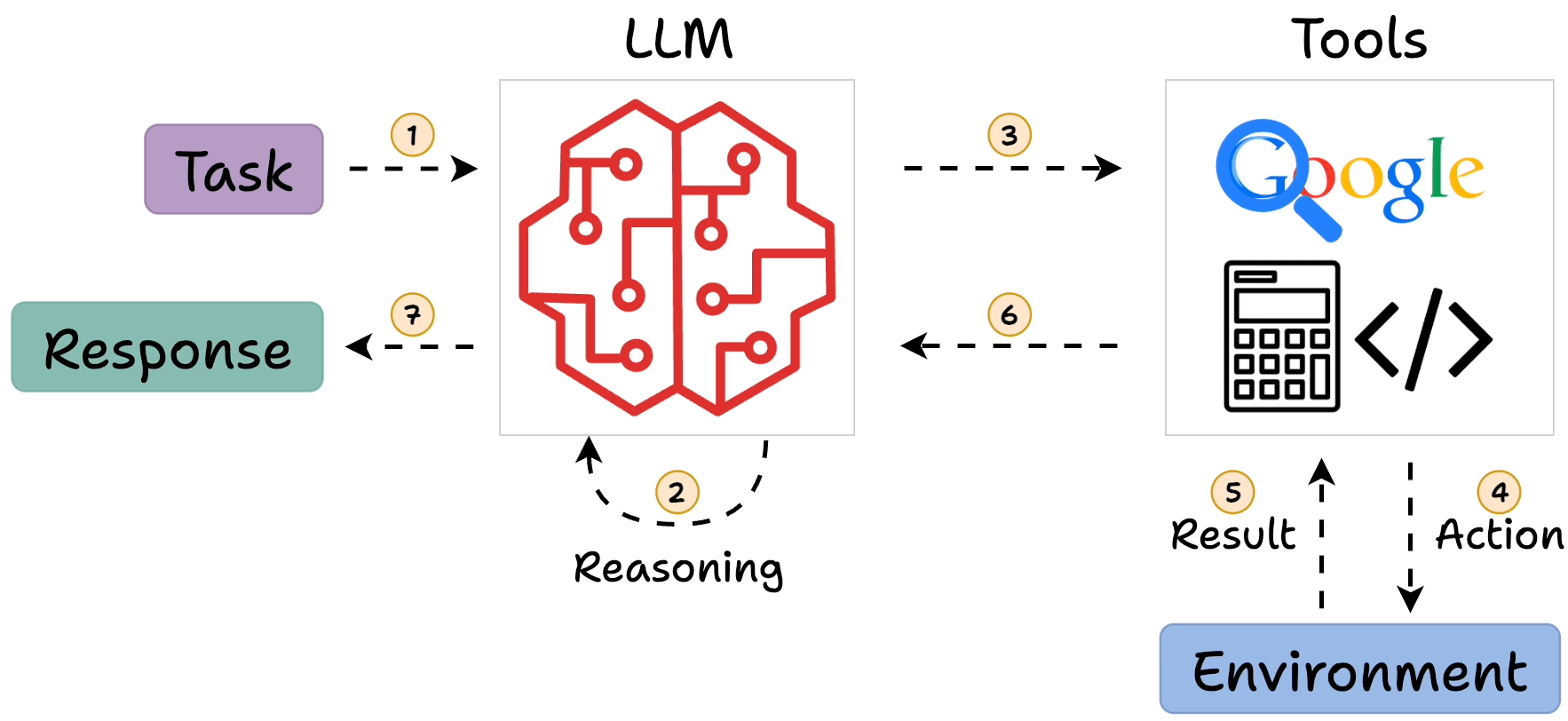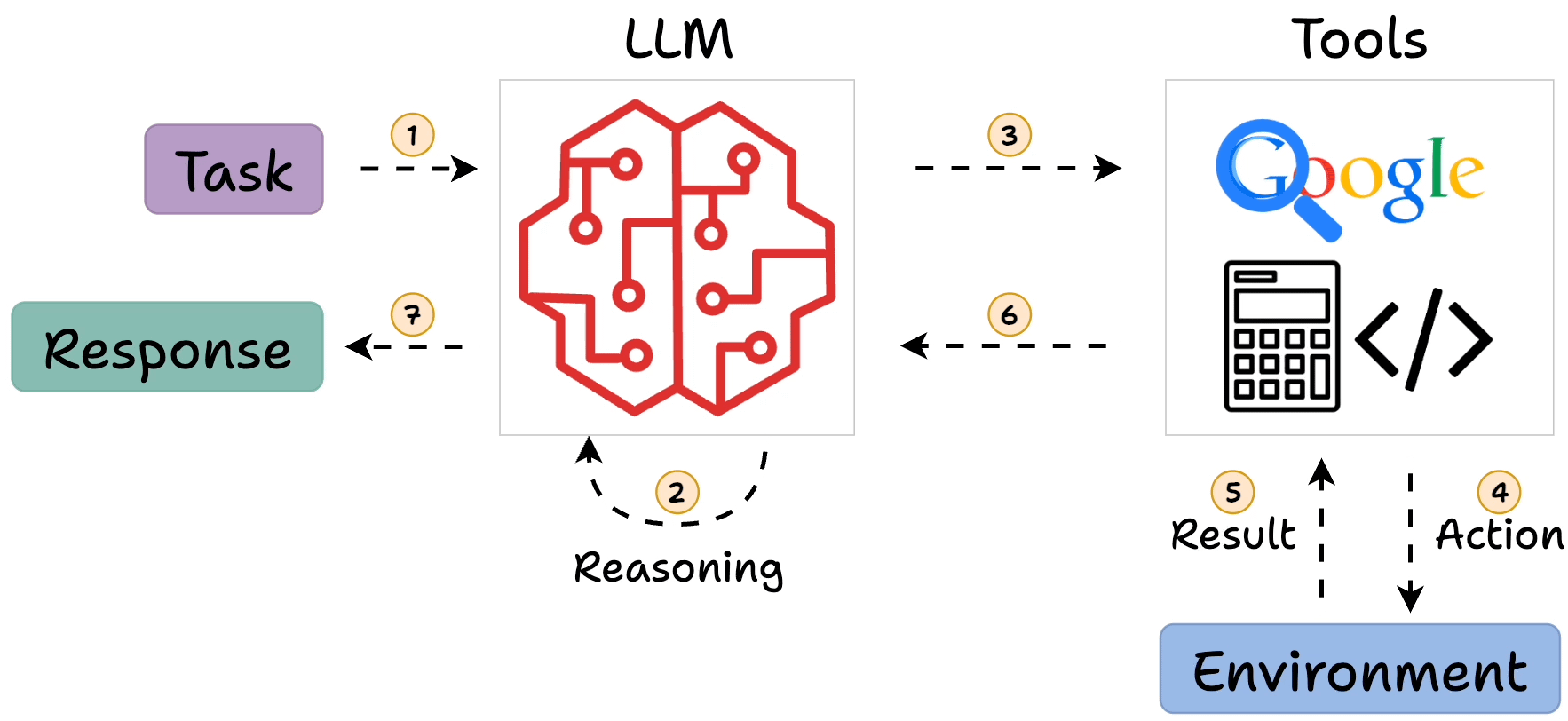
In ReAct, the LLM generates a “thought” to plan, selects an “action” from available tools, observes the outcome, and iterates. This loop continues until the model outputs a final answer. For example, answering “What is Olivia Wilde’s boyfriend’s age raised to the 0.23 power?” might involve searching for the boyfriend, then calculating the power.
 Source: Internet
Source: Internet
Key Points
- ReAct Framework: It seems likely that ReAct is a prompting technique enabling LLMs to alternate between reasoning (thinking step-by-step) and acting (using tools like searches or calculations), improving accuracy on complex tasks by reducing hallucinations and incorporating external information.
- Core Process: Evidence leans toward a loop of Thought (reasoning), Action (tool invocation), Observation (results), repeating until a final answer, mimicking human problem-solving.
- Benefits and Limitations: Research suggests ReAct enhances interpretability and performance on knowledge-intensive and decision-making tasks, though it may increase computational costs and rely on well-defined tools; it’s particularly useful for dynamic environments but less so for simple queries.
Foundations of ReAct
ReAct was introduced in the 2022 paper “ReAct: Synergizing Reasoning and Acting in Language Models” by Shunyu Yao et al. It builds on chain-of-thought (CoT) prompting, where LLMs break down problems into intermediate reasoning steps for better performance on tasks like arithmetic or commonsense reasoning. However, CoT relies solely on the model’s internal knowledge, leading to issues like factual errors or outdated information.
ReAct addresses this by interleaving reasoning (“thoughts”) with actions, allowing the model to query external sources (e.g., search engines, calculators, or databases) and incorporate observations back into its reasoning process. This creates a feedback loop inspired by human cognition: think, act, observe, and adjust. As of 2025, ReAct remains a cornerstone for building LLM agents, integrated into frameworks like LangChain and LangGraph, with enhancements for multi-agent systems and reduced latency.
Key components include:
- Thought: A verbalized reasoning step where the LLM plans or reflects.
- Action: Invocation of a tool, such as searching Wikipedia or running a calculation.
- Observation: The result from the action, fed back to the LLM.
- Final Answer: Output when the loop concludes, often after several iterations.
This structure improves trustworthiness by making the process interpretable—users can trace how the model arrived at an answer.
How ReAct Works: A Step-by-Step Breakdown
ReAct operates in an iterative loop, typically capped at a maximum number of turns to control costs and latency. Here’s the flow:
- Initialization: The LLM receives a prompt outlining the ReAct format (e.g., “You run in a loop of Thought, Action, PAUSE, Observation”).
- Thought Generation: The model reasons about the query, deciding on the next action.
- Action Execution: If an action is needed, the system pauses, executes the tool, and returns an observation.
- Observation Integration: The observation is appended to the prompt, and the loop repeats.
- Termination: The model outputs “Answer” when confident, or hits the iteration limit.
For instance, in a knowledge-intensive task like HotpotQA (multi-hop question answering), ReAct might search for “Colorado orogeny,” observe the result, reason about the eastern sector, and lookup further details until answering the elevation range.
ReAct excels in domains like:
- Knowledge Tasks: Outperforms CoT by accessing external info, reducing hallucinations.
- Decision-Making: Handles interactive environments (e.g., games or web navigation) via tools.
- Agentic Workflows: Integrates with RAG or multi-agent systems for complex automation.
However, challenges include dependency on tool quality, potential for infinite loops without safeguards, and higher token usage compared to simpler prompts.
Comparisons: ReAct vs. Other LLM Techniques
To contextualize ReAct, consider this comparison table:
| Technique | Description | Strengths | Weaknesses | Use Cases |
|---|---|---|---|---|
| Chain-of-Thought (CoT) | Prompts LLMs to reason step-by-step without external actions. | Simple, low-cost; good for internal logic. | Prone to hallucinations; no real-world interaction. | Arithmetic, commonsense QA. |
| ReAct | Interleaves reasoning with tool-based actions and observations. | Dynamic, factual; interpretable loop. | Higher latency; tool-dependent. | Multi-hop QA, web tasks, agents. |
| Function Calling | Fine-tuned models output JSON for tool calls, without explicit reasoning. | Fast, structured; efficient for predictable tasks. | Less adaptable; opaque reasoning. | API integrations, simple tools. |
| ReAct + CoT | Hybrid: Uses ReAct for actions and CoT for pure reasoning switches. | Optimal performance; flexible. | Complex implementation. | Advanced agents, hybrid tasks. |
ReAct often outperforms baselines on benchmarks like HotpotQA, Fever, ALFWorld, and WebShop, with gains in accuracy and efficiency when combined with CoT.
Building a Sample ReAct Application in Python
A basic ReAct agent can be built using Python libraries like LangChain. The sample below creates an agent that searches the web and performs math, demonstrating the loop in action. You’ll need API keys for an LLM (e.g., OpenAI) and tools (e.g., Google Serper for search). For full code and setup, see the detailed survey below. This sample creates an agent that answers questions by searching the web (via Tavily) and performing calculations. It demonstrates the full loop and includes conversational memory for multi-turn interactions.
Prerequisites
- Python 3.10+.
- Install dependencies:
pip install -U langgraph langchain-tavily langgraph-checkpoint-sqlite langchain-openai. - API Keys: Obtain OpenAI (for the LLM) and Tavily (for search) keys. Set them as environment variables:
python import os import getpass os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key: ") os.environ["TAVILY_API_KEY"] = getpass.getpass("Tavily API Key: ") - For tracing (optional): Set LangSmith keys.
Code Implementation
The application uses LangGraph’s create_react_agent for the ReAct logic. Here’s the complete code:
# Import necessary modules
from langchain_tavily import TavilySearchResults
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpointer import MemorySaver
from langchain_core.messages import HumanMessage
# Define tools
tool = TavilySearchResults(max_results=2)
tools = [tool]
# Initialize the LLM (using OpenAI's GPT-4o-mini for efficiency)
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Bind tools to the model
model_with_tools = model.bind_tools(tools)
# Create the agent with memory (using MemorySaver for conversational state)
memory = MemorySaver()
agent_executor = create_react_agent(model_with_tools, tools, checkpointer=memory)
# Configuration for conversational thread (use a unique ID for each conversation)
config = {"configurable": {"thread_id": "conversation-1"}}
# Function to run the agent
def run_agent(query):
print(f"User Query: {query}")
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content=query)]}, config
):
print(chunk)
print("----")
# Extract final response
response = chunk.get("agent", {}).get("messages", [{}])[0].content
return response
# Example usage
query = "Who is the current CEO of xAI? What is their age squared?"
response = run_agent(query)
print(f"Final Answer: {response}")
Detailed Explanation
- Tools Definition:
TavilySearchResultsis a web search tool returning up to 2 results. It’s added totoolsfor the agent to use. - LLM Setup:
ChatOpenAIinitializes the model (e.g., GPT-4o-mini for cost-effectiveness).bind_toolsinforms the model about available actions. - Agent Creation:
create_react_agentbuilds the ReAct loop, withMemorySaverenabling state persistence for follow-ups (e.g., “Tell me more about them”). - Execution: The
streammethod runs the agent, printing intermediate thoughts, actions, and observations. For the example query:- Thought: Reason about searching for xAI CEO.
- Action: Invoke Tavily search.
- Observation: Retrieve CEO (e.g., Elon Musk) and age.
- Thought: Calculate age squared.
- Final Answer: Output the result (e.g., “Elon Musk, age 54 squared is 2916”).
- Extensions: Add more tools (e.g., math via
LLMMathChain) or integrate with databases for custom applications.
Testing and Output
Running the code might yield:
- Intermediate: Thought → Action (search) → Observation → Thought (calculate) → Answer. This ensures factual grounding, e.g., verifying current data as of 2025.
Advanced Variations and Best Practices
- Simple Non-LangChain Implementation: For a lightweight version, use a custom loop with OpenAI’s API, as in Simon Willison’s example. Define actions like
wikipediaand parse responses with regex. - With LangGraph: For production, use LangGraph for visual workflows and error handling.
- Best Practices: Limit iterations (e.g., max_turns=5), use verbose mode for debugging, and combine with CoT for hybrid prompting. Monitor token usage, as ReAct can be resource-intensive.
- 2025 Updates: Recent integrations include multimodal support (e.g., image analysis tools) and edge deployment for low-latency agents.
Conclusion
ReAct represents a pivotal shift toward agentic AI, empowering LLMs to not just generate text but actively engage with the world. By implementing the sample above, developers can experiment and scale to real-world applications like automated research or virtual assistants.