Understanding Types of Large Language Models (LLMs)
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) with their ability to understand, generate, and interact with human language. These models are built using deep learning techniques and have been trained on vast amounts of text data. In this blog, we will explore the different types of LLMs, their architectures, and their applications.
Generative Pre-trained Transformers (GPT)
Overview
GPT models, developed by OpenAI, are among the most popular LLMs. They use a transformer-based architecture and are designed to generate human-like text. The models are pre-trained on a large corpus of text and then fine-tuned for specific tasks.
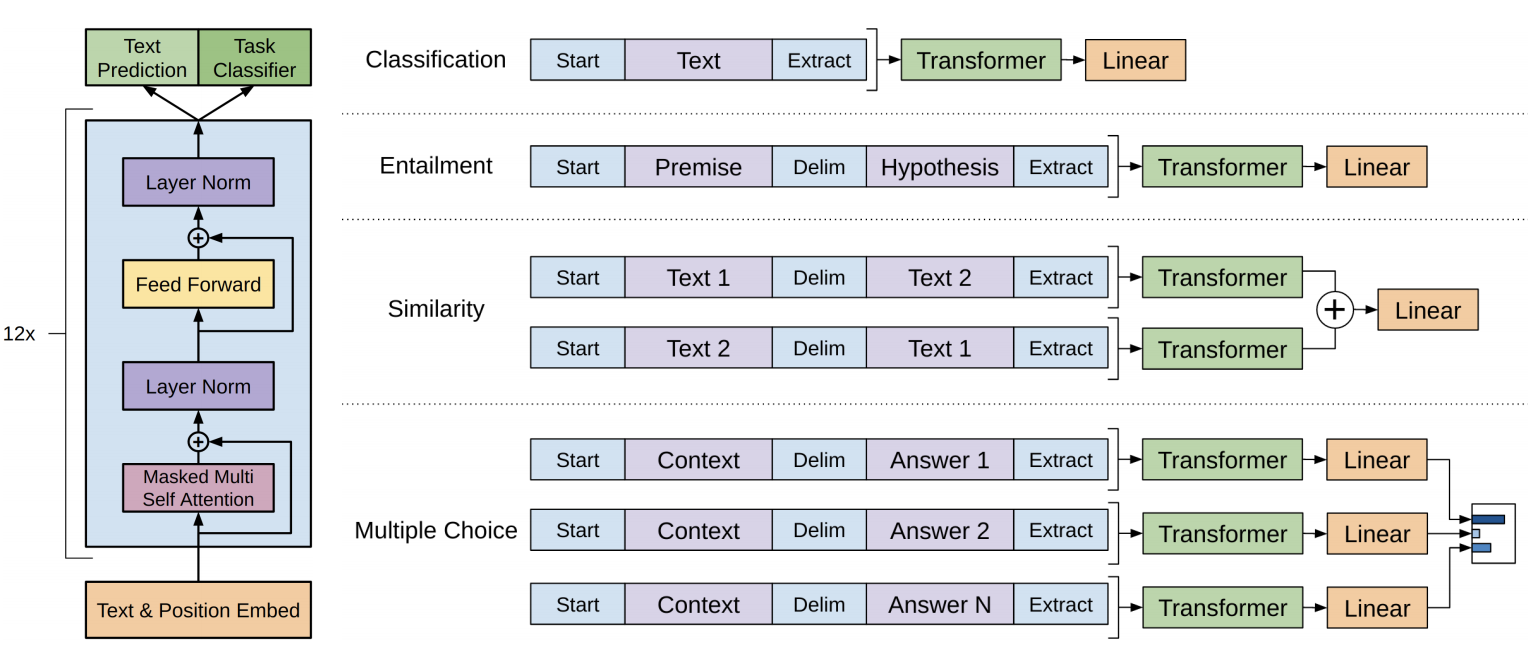 Source: Internet
Source: Internet
Key Features
- Transformer Architecture: Utilizes self-attention mechanisms to process input text efficiently.
- Pre-training and Fine-tuning: Initially pre-trained on diverse text data and then fine-tuned for specific tasks like language translation, summarization, and question answering.
- Generative Capabilities: Can generate coherent and contextually relevant text based on a given prompt.
Applications
- Chatbots and virtual assistants
- Text completion and generation
- Content creation
Bidirectional Encoder Representations from Transformers (BERT)
Overview
BERT, developed by Google, is designed for understanding the context of words in a sentence. Unlike GPT, which generates text, BERT excels at tasks requiring a deep understanding of text, such as question answering and sentiment analysis.
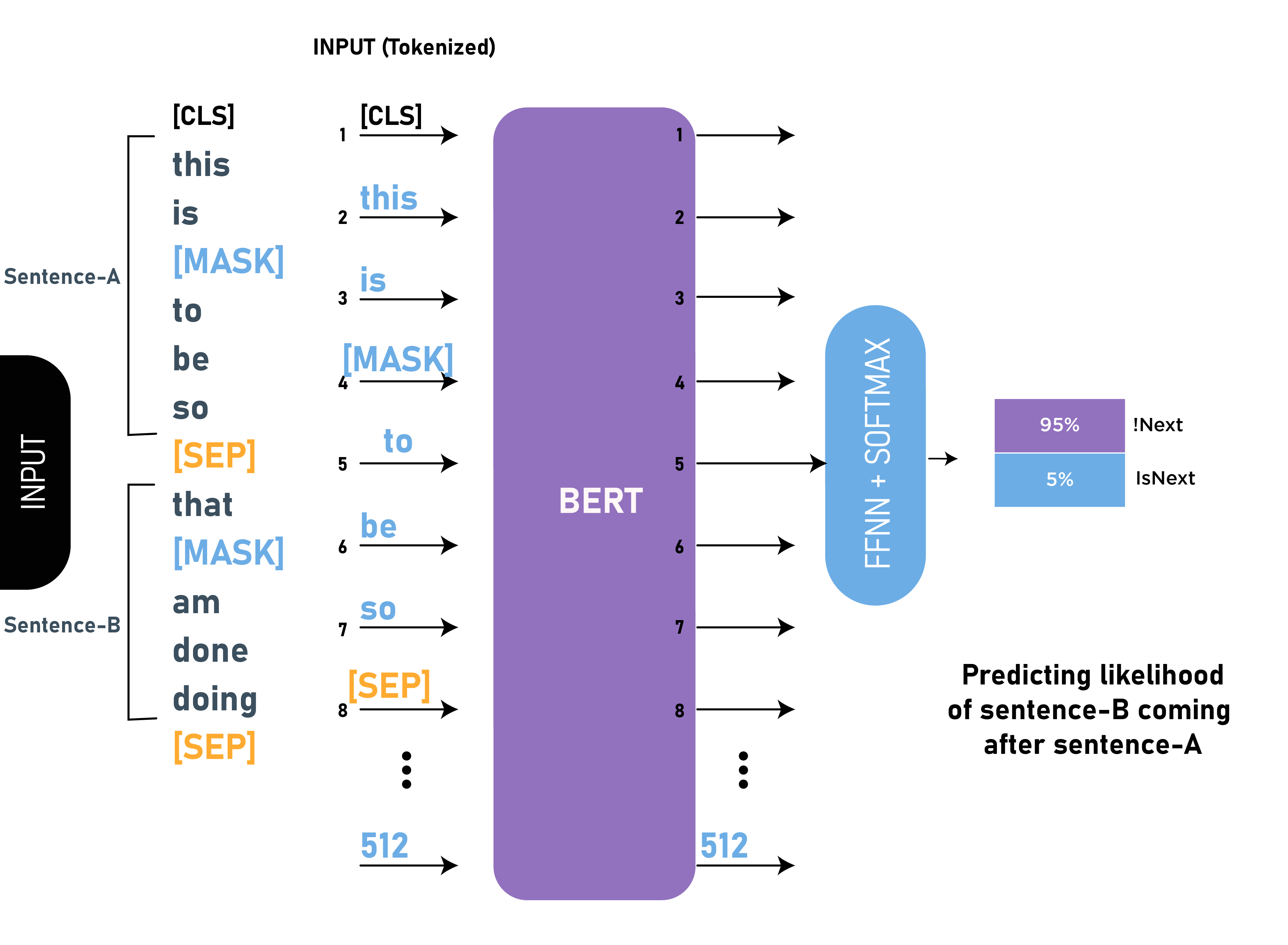 Source: Internet
Source: Internet
Key Features
- Bidirectional Training: BERT reads text in both directions (left-to-right and right-to-left) to capture context more effectively.
- Masked Language Modeling (MLM): Trained by predicting masked words in a sentence, enabling it to understand the context of each word.
- Next Sentence Prediction (NSP): Helps the model understand the relationship between sentences.
Applications
- Question answering systems
- Sentiment analysis
- Text classification
T5 (Text-to-Text Transfer Transformer)
Overview
T5, also developed by Google, treats every NLP task as a text-to-text problem. This means both the input and the output are text strings, making it highly versatile for various tasks.
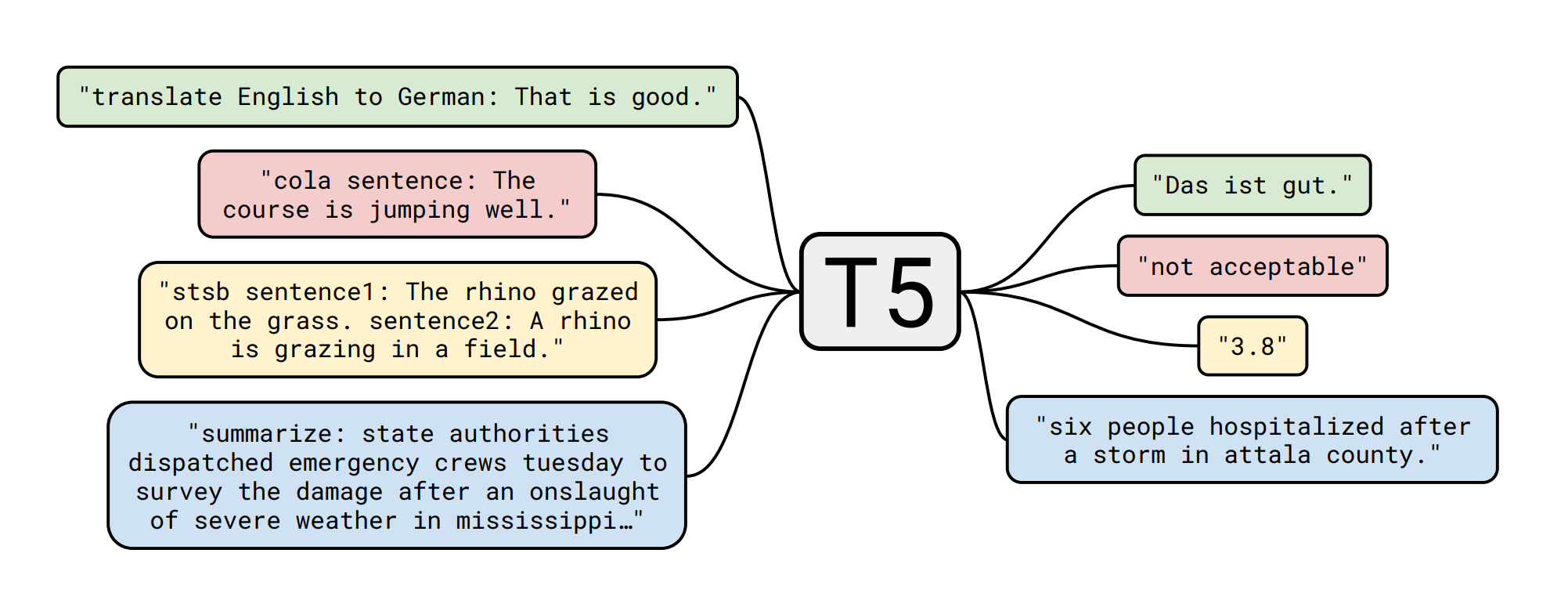 Source: Internet
Source: Internet
Key Features
- Unified Framework: Simplifies the model by converting all tasks into a text-to-text format.
- Pre-training on Diverse Tasks: Pre-trained on a mixture of unsupervised and supervised tasks, enabling it to generalize well.
- Flexibility: Can be fine-tuned for a wide range of tasks such as translation, summarization, and classification.
Applications
- Machine translation
- Text summarization
- Sentence paraphrasing
XLNet
Overview
XLNet, developed by Google and Carnegie Mellon University, aims to improve upon BERT by addressing its limitations. It uses a permutation-based training method to capture bidirectional context without masking.
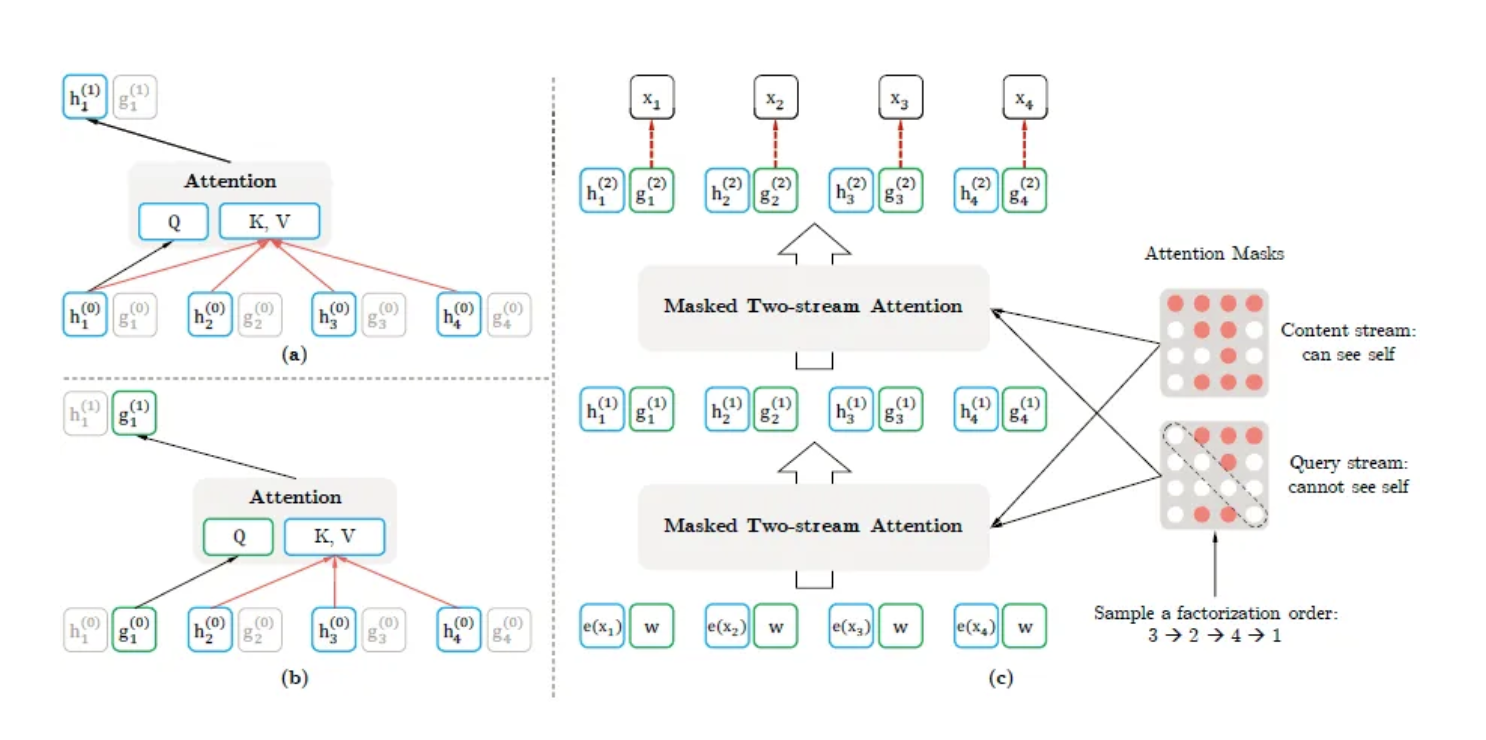 Source: Internet
Source: Internet
Key Features
- Permutation Language Modeling: Instead of masking, XLNet predicts all tokens in a sentence in random order, preserving context for each word.
- Autoregressive Method: Combines the strengths of autoregressive models (like GPT) with bidirectional context.
- Improved Performance: Outperforms BERT on several NLP benchmarks.
Applications
- Reading comprehension
- Text classification
- Sentence completion
Robustly Optimized BERT Pretraining Approach (RoBERTa)
Overview
RoBERTa, developed by Facebook AI, is an optimized version of BERT. It focuses on improving BERT’s performance by making changes to the training procedure.
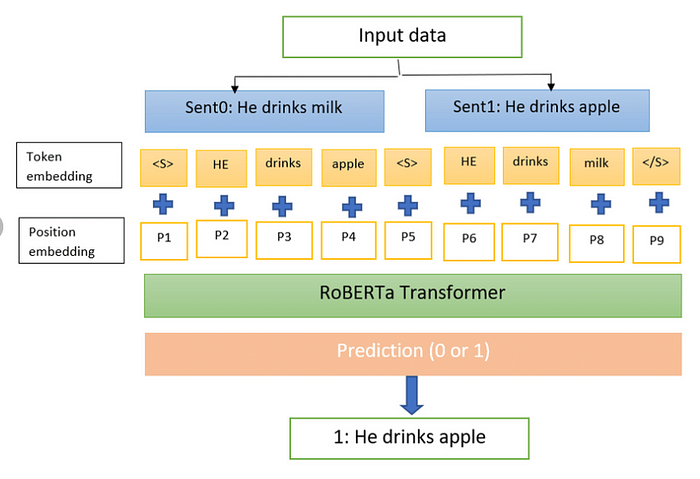 Source: Internet
Source: Internet
Key Features
- Larger Training Data: Trained on more data and for longer periods compared to BERT.
- Dynamic Masking: Uses a different masking pattern for each epoch during training.
- No NSP Task: Removes the next sentence prediction task, focusing solely on masked language modeling.
Applications
- Sentiment analysis
- Named entity recognition
- Text classification
Conclusion
Large Language Models have significantly advanced the field of NLP, offering powerful tools for understanding and generating human language. Each type of LLM has its strengths and is suited for different applications. As these models continue to evolve, they promise to unlock new possibilities in various domains, from enhancing virtual assistants to enabling more sophisticated language understanding systems.
Understanding the differences between these models helps in selecting the right tool for specific tasks and leveraging their full potential. Whether it’s the generative prowess of GPT, the contextual understanding of BERT, or the versatility of T5, LLMs are reshaping how we interact with and utilize language in the digital age.