Vector Database: Transforming Data Storage and Retrieval in the AI Era
The AI revolution has ushered in a new era of innovation, promising breakthroughs across various industries. However, with these advancements come unique challenges, particularly in handling and processing data efficiently. One of the key data types that have gained prominence in AI applications is vector embeddings. Vector databases play a pivotal role in managing and optimizing the retrieval of these embeddings. In this article, we will explore the architecture of vector databases and their crucial role in AI applications.
What is a Vector Database?
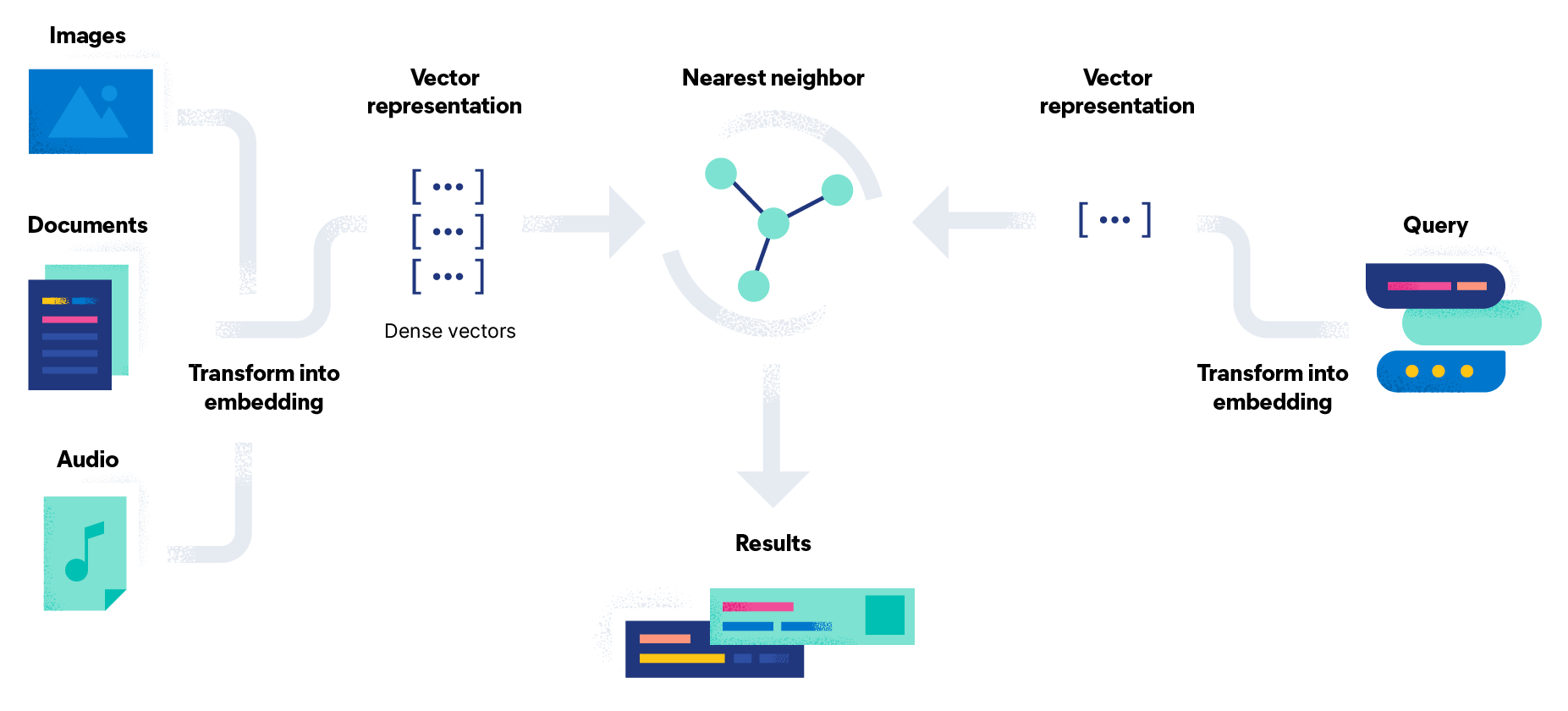
A vector database is a specialized database designed to index and store vector embeddings for efficient retrieval and similarity search. These databases offer not only CRUD (Create, Read, Update, Delete) operations but also advanced capabilities like metadata filtering and horizontal scaling. They are essential for AI applications that rely on vector embeddings to understand patterns, relationships, and underlying structures in data.
 Source: Elastic
Source: Elastic
Vector Embeddings
Vector embeddings are data representations generated by AI models, such as large language models. They encapsulate semantic information critical for AI to understand and perform complex tasks effectively. These embeddings have multiple attributes or features, making their management a unique challenge.
Traditional scalar-based databases struggle to handle the complexity and scale of vector data, hindering real-time analysis and insights extraction. Vector databases are tailored to address these limitations, providing the performance, scalability, and flexibility needed for extracting valuable insights from vector embeddings.
Vector Database Architecture
Traditional databases store scalar data in rows and columns, whereas vector databases operate on vectors. They differ in the way data is optimized and queried.
In traditional databases, queries typically seek exact matches between query values and database records. In vector databases, similarity metrics are applied to find vectors that are most similar to the query. Vector databases employ a combination of algorithms to enable Approximate Nearest Neighbor (ANN) searches, which optimize retrieval speed.
Vector Database Pipeline
A typical vector database pipeline consists of the following stages:
 Source: Pinecone
Source: Pinecone
Indexing: The database indexes vectors using algorithms like PQ (Product Quantization), LSH (Locality-Sensitive Hashing), or HNSW (Hierarchical Navigable Small World). This step maps vectors to data structures for faster searching.
Querying: The database compares the indexed query vector to the indexed vectors in the dataset to find the nearest neighbors, applying a similarity metric used by the index.
Post Processing: In some cases, the database retrieves the final nearest neighbors from the dataset and may post-process them, such as re-ranking them using a different similarity measure.
Algorithms for Vector Indexing
Vector databases rely on various algorithms to create efficient indexes for high-dimensional vector embeddings. These algorithms are designed to transform the original vector data into a compressed form, optimizing the query process for faster retrieval.
Random Projection
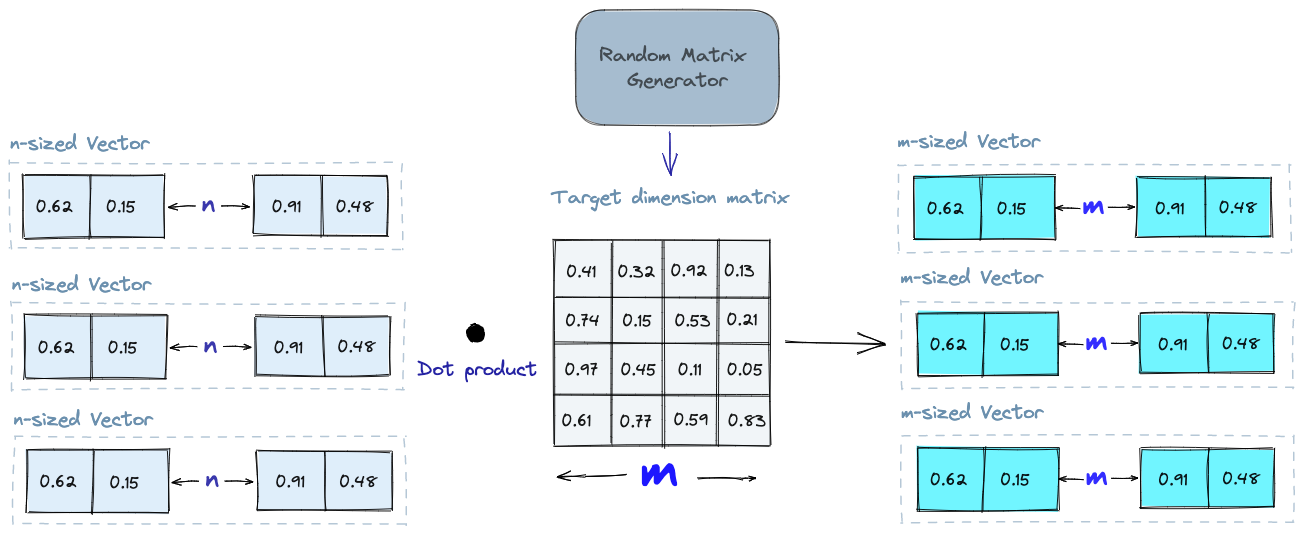
Random projection is a technique that aims to project high-dimensional vectors into a lower-dimensional space using a random projection matrix. Here’s how it works:
Projection Matrix Creation: A matrix of random numbers is created with the target lower-dimensional value. This matrix is then used to calculate the dot product of input vectors, resulting in a projected matrix that has fewer dimensions but still preserves vector similarity.
Query Process: When a query is executed, the same projection matrix is used to project the query vector into the lower-dimensional space. The projected query vector is then compared to the projected vectors in the database to find the nearest neighbors. The reduced dimensionality of the data speeds up the search process.
It’s essential to note that random projection is an approximate method, and the quality of the projection depends on the properties of the projection matrix. Generating a truly random projection matrix can be computationally expensive, especially for large datasets.
 Source: Pinecone
Source: Pinecone
Product Quantization
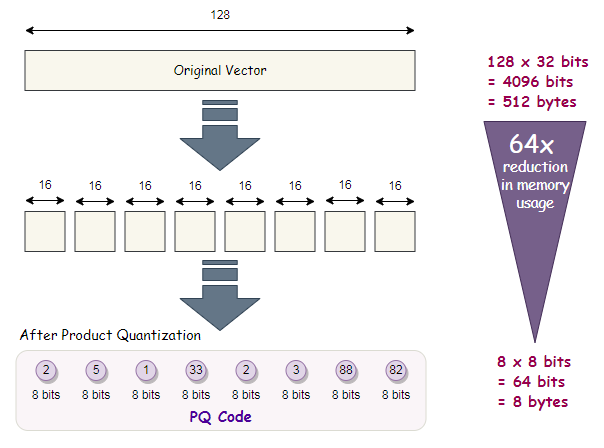
Product quantization (PQ) is a lossy compression technique tailored for high-dimensional vectors, such as vector embeddings. The process involves splitting, training, encoding, and querying:
Splitting: Vectors are divided into segments.
Training: A “codebook” is created for each segment, representing potential codes for vectors. The codebook is established by performing k-means clustering on each segment, resulting in center points that serve as codes.
Encoding: Each vector segment is assigned a specific code from the codebook, typically the nearest value. Multiple PQ codes can represent a segment.
Query Process: During querying, vectors are broken down into sub-vectors and quantized using the codebook. The indexed codes are then used to find the nearest vectors to the query vector.
The number of representative vectors in the codebook involves a trade-off between representation accuracy and computational cost. A larger codebook improves accuracy but increases computational expenses.
 Source: Towards Data Science
Source: Towards Data Science
Locality-Sensitive Hashing (LSH)
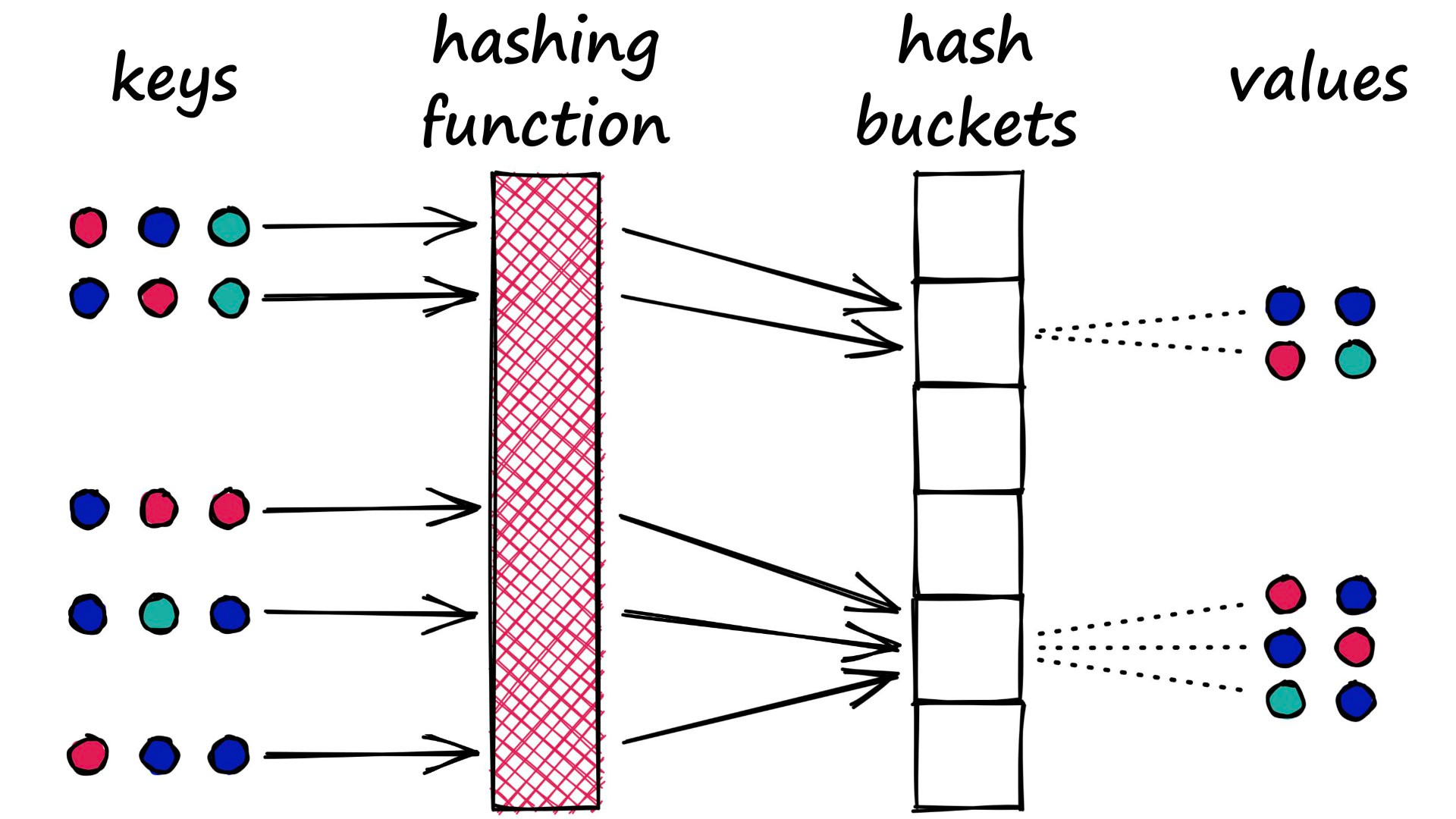
Locality-sensitive hashing (LSH) is optimized for approximate nearest-neighbor search. LSH maps similar vectors into “buckets” using a set of hashing functions:
Indexing: Similar vectors are grouped into hash tables using the hashing functions.
Query Process: To find the nearest neighbors for a query vector, the same hashing functions are used to map the query vector to a specific table. The query vector is then compared with the vectors in that table to find the closest matches. This method accelerates searching by reducing the number of vectors to consider.
LSH is an approximate method, and the quality of the approximation depends on the properties of the hash functions. Using more hash functions improves approximation quality but can be computationally expensive, especially for large datasets.
 Source: Pinecone
Source: Pinecone
Hierarchical Navigable Small World (HNSW)
HNSW creates a hierarchical, tree-like structure where each node represents a set of vectors, and edges indicate similarity between vectors. The algorithm follows these steps:
Node Creation: A set of nodes is established, each containing a small number of vectors. Nodes can be created randomly or by clustering vectors using algorithms like k-means.
Edge Formation: The algorithm examines the vectors within each node and establishes edges between the node and those nodes containing the most similar vectors.
Query Process: When querying an HNSW index, the algorithm navigates the hierarchical structure, visiting nodes that are likely to contain the closest vectors to the query vector.
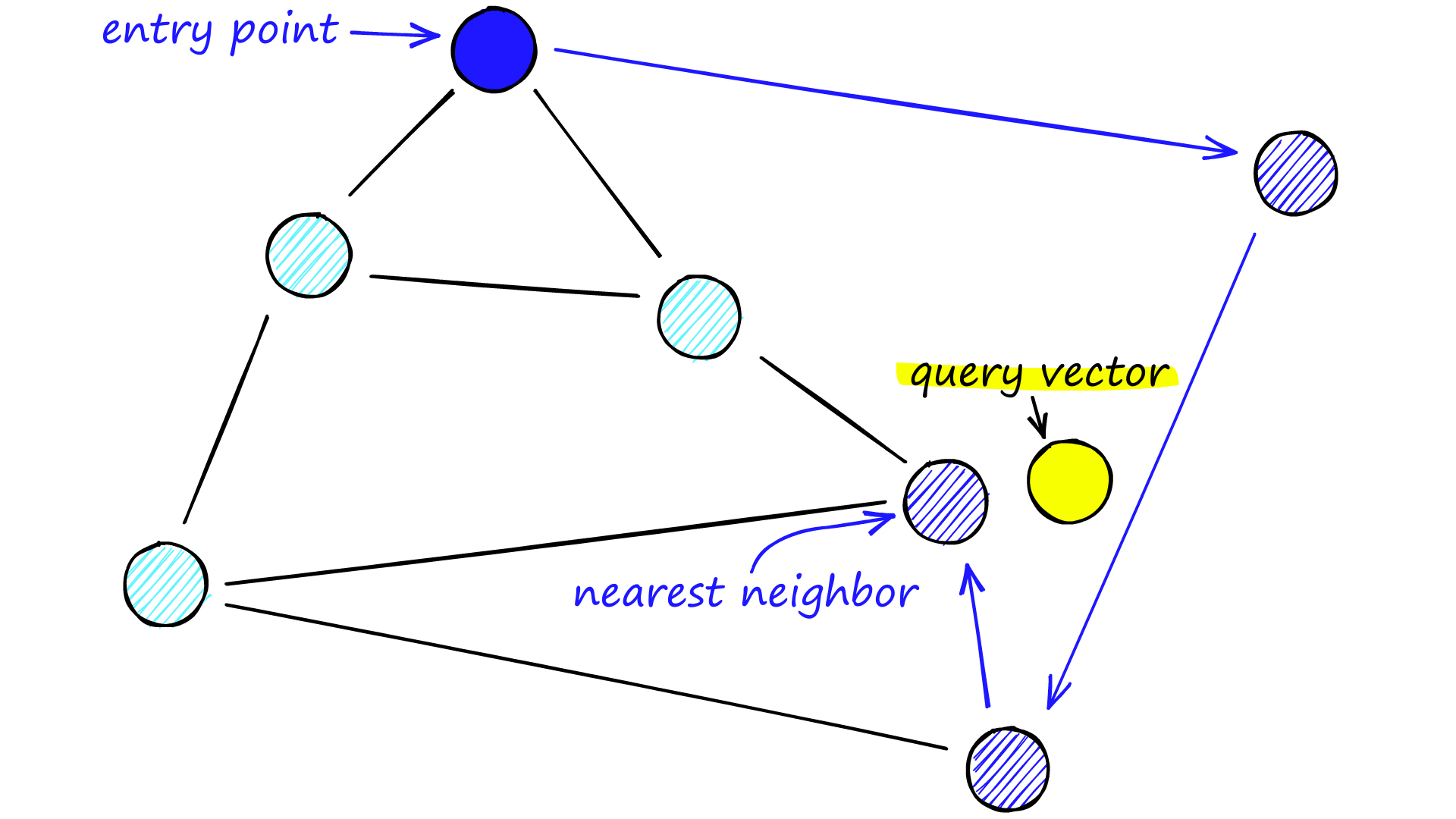 Source: Pinecone
Source: Pinecone
Similarity Measures
The choice of similarity measure plays a crucial role in vector database performance. Common similarity measures include:
Cosine Similarity: Measures the cosine of the angle between two vectors, with a range from -1 to 1. It signifies the degree of similarity between vectors.
Euclidean Distance: Measures the straight-line distance between vectors in a vector space, with a range from 0 to infinity.
Dot Product: Measures the product of the magnitudes of two vectors and the cosine of the angle between them, with a range from -∞ to ∞.
The selection of the appropriate similarity measure depends on the specific use case and requirements.
Filtering
Each vector stored in the database includes associated metadata. Vector databases can filter query results based on metadata queries, typically maintaining both vector and metadata indexes. The filtering process can occur before or after the vector search, with trade-offs in terms of efficiency.
Pre-filtering: Filters are applied before the vector search. While reducing the search space, it may exclude relevant results not meeting metadata filter criteria and add computational overhead.
Post-filtering: Filters are applied after the vector search. This ensures all relevant results are considered but may introduce additional processing overhead.
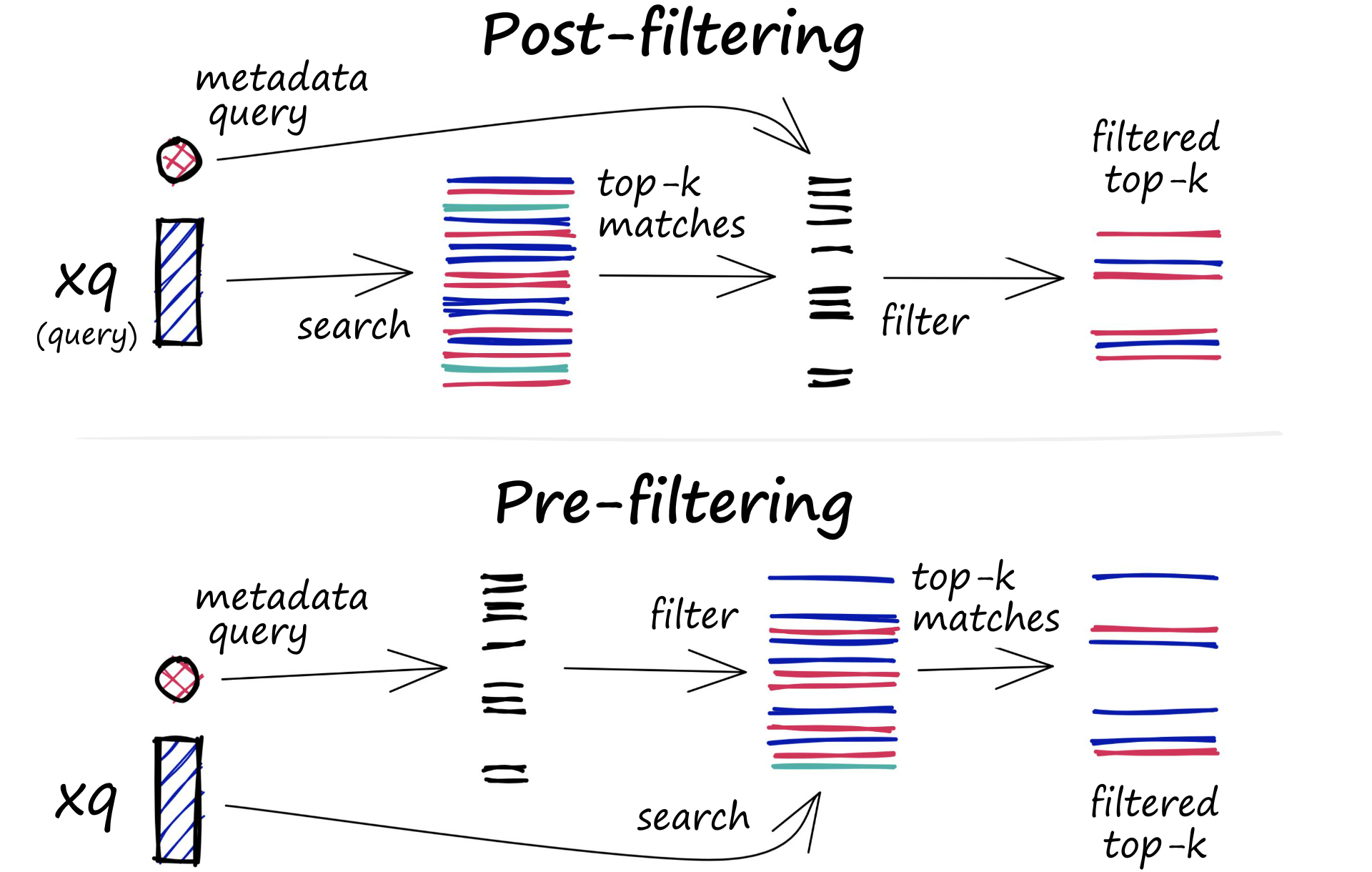 Source: Pinecone
Source: Pinecone
Optimizing the filtering process involves techniques like advanced indexing for metadata and parallel processing to balance performance and accuracy.
Vector Database vs. Vector Index
While standalone vector indices like FAISS (Facebook AI Similarity Search) can enhance the search and retrieval of vector embeddings, they lack essential database features. Vector databases offer several advantages over standalone vector indices, including:
Data Management: Vector databases provide traditional database features for easy data management, such as insertion, deletion, and updating. This simplifies vector data management compared to standalone vector indices like FAISS, which require additional integration with storage solutions.
Metadata Storage and Filtering: Vector databases can store metadata associated with each vector entry. Users can query the database using additional metadata filters for more granular queries.
Scalability: Vector databases are designed for scalability, supporting the growth of data volumes and user demands. They excel in distributed and parallel processing, while standalone vector indices may require custom solutions for similar scalability.
Real-time Updates: Vector databases often support real-time data updates, allowing dynamic changes to the data. Standalone vector indexes may require time-consuming and computationally expensive full re-indexing to incorporate new data.
Backups and Collections: Vector databases handle data backup operations, and users can selectively choose specific indexes to back up in the form of “collections.” This feature ensures data resilience and retrievability.
Ecosystem Integration: Vector databases can seamlessly integrate with other components of a data processing ecosystem, streamlining data management workflows. This integration extends to AI-related tools, fostering a comprehensive ecosystem for AI applications.
Data Security and Access Control: Vector databases typically include built-in data security features and access control mechanisms to safeguard sensitive information. These security measures may not be available in standalone vector index solutions.
In summary, vector databases are purpose-built for managing vector embeddings, addressing the limitations of standalone vector indices and offering a more effective and streamlined data management experience.
Conclusion
In the age of AI, efficient data processing and retrieval are paramount for applications relying on vector embeddings. Vector databases are purpose-built to handle these complex data types, offering advanced capabilities for storage, retrieval, and analysis. Understanding the architecture and capabilities of vector databases empowers organizations to unlock the full potential of their AI applications, gaining a competitive edge in the rapidly evolving AI landscape.