When Size Isn’t Everything: Why Sapient’s 27M-Parameter HRM Matters for Small Models & AGI
What is HRM (and why we should care)
Singapore’s Sapient Intelligence introduced the Hierarchical Reasoning Model (HRM) — a 27M-parameter, brain-inspired, multi-timescale recurrent architecture trained with just 1,000 examples and no pre-training. According to the authors (arxiv.org), HRM outperforms GPT-o3-mini and Claude on the ARC-AGI benchmark, a test designed to measure genuine inductive reasoning rather than pattern replication.
The design mirrors cognitive neuroscience: the brain separates slow, global planning from fast, fine-grained execution. HRM encodes these separate timescales directly into its architecture.
Empirical Results
Sapient reports:
- ARC-AGI: HRM surpasses o3-mini-high, Claude 3.7 (8K), and DeepSeek R1 on Sapient’s internal ARC-AGI evaluations (coverage).
- Structured reasoning tasks: Near-perfect results on Sudoku-Extreme and 30×30 Maze-Hard, where chain-of-thought-dependent LLMs typically break down.
- Efficiency profile:
- ~1,000 labeled examples
- Zero pre-training
- No chain-of-thought supervision
- Single-pass inference
- Over 90% reduction in compute relative to typical LLM reasoning pipelines (ACN Newswire)
The data suggests that architectural inductive bias can outperform sheer parameter scale.
How HRM Works
Hierarchical, Multi-Timescale Architecture
HRM is composed of two interconnected recurrent modules:
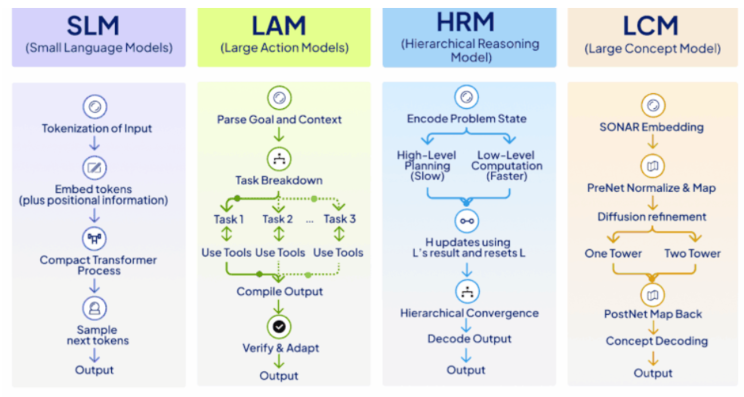
High-Level Planner
Slow, abstract reasoning. Responsible for decomposing tasks and constructing coarse strategies.Low-Level Executor
Fast, detail-oriented operations. Executes logical steps required to satisfy the planner’s subgoals.
This coupled dynamic creates effective depth similar to a deep transformer stack, but with orders of magnitude fewer parameters.
No Chain-of-Thought, No Pre-Training
HRM does not rely on chain-of-thought prompting, large-scale text corpora, or instruction tuning. It performs all reasoning internally and outputs only the final answer.
Benefits include:
- Lower latency
- Lower memory footprint
- Fewer multi-step hallucination/error cascades
- Simplified deployment on constrained hardware
Data & Compute Efficiency
By learning directly from end-to-end examples, HRM avoids:
- Billion-token pre-training cycles
- Long-context inference costs
- Model distillation or supervised CoT pipelines
Limitations and Open Questions
Although compelling, HRM is not a general-purpose language model:
- Domain narrowness: Designed for puzzles and abstract reasoning, not open-domain tasks.
- Reproducibility: Independent results are still sparse.
- Generalization: Unclear whether this architecture scales to real-world, noisy environments.
- Opacity: No emitted reasoning trace makes interpretation and debugging harder.
A recent study argues that a 7M-parameter Tiny Recursive Model (TRM) can surpass HRM on ARC-AGI (arxiv.org), hinting that recursion, not hierarchy, may be the core enabler.
Implications: Are Small Models Catching Up?
HRM signals a possible shift in how we think about reasoning systems:
- Compute accessibility: A 27M-parameter reasoning engine can run on laptops, edge devices, and mid-tier servers.
- Sparse-data advantages: Scientific reasoning, robotics, and rare-event domains may benefit from models that do not require massive corpora.
- Hybrid architectures: A small HRM-like module for symbolic reasoning paired with a large LLM for language grounding and world knowledge.

Architectural bias may matter as much as — or more than — raw parameter count.
What to Watch
- Independent replications of ARC-AGI results
- Extensions to messy real-world domains
- LLMs adopting multi-timescale planning modules
- New interpretability techniques for non-CoT models
HRM doesn’t replace large LLMs, but it questions the assumption that scale alone produces genuine reasoning. The next advances may come from architectural choices rather than parameter inflation.